How to use SciServer
This page provides links, help guides, and other resources for the SciServer suite of tools.
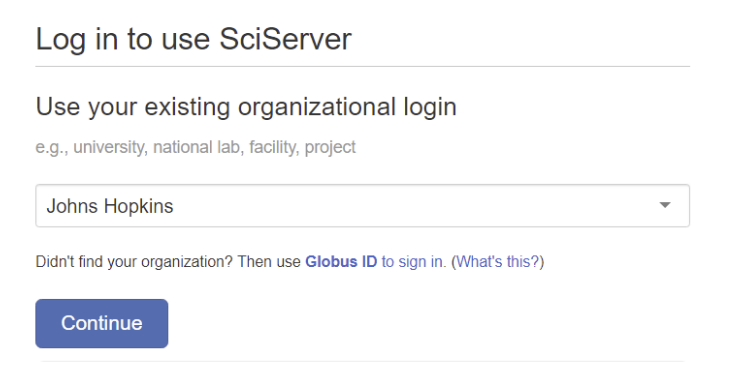
- From the SciServer home page, click the Login to SciServer button
- A new page opens containing the SciServer Login Portal
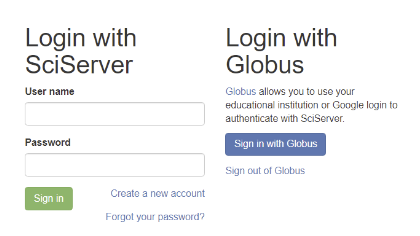
- You will see there are two ways to log in to SciServer:
- with a SciServer account
- with a linked Globus account
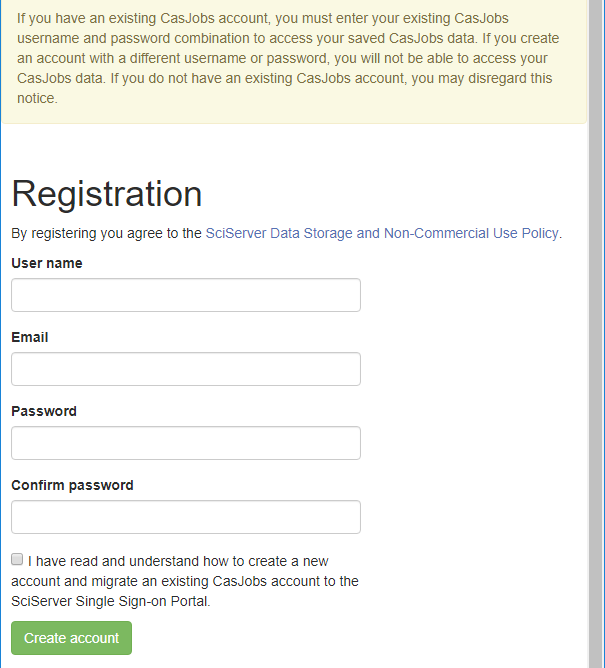
- To create a new SciServer account, click on the Create a new account link
- At the Registration page, enter the following:
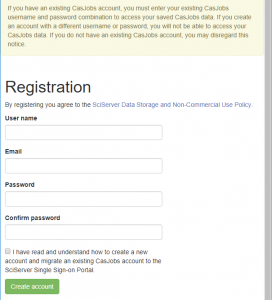
-
- User name
- Password (twice)
- Check the box to confirm the terms of service
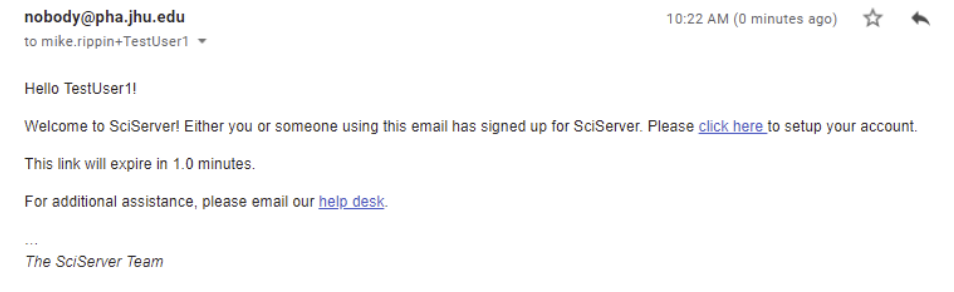
- Then click Create Account, which will send you an email and display the following note:

- Open the email and click the click here link.
- This will automatically log you in as a new user, with the username you specified. You will begin on the SciServer Dashboard home page.
-
- From the SciServer home page, click the Login to SciServer button
- A new page opens containing the SciServer Login Portal
- You will see there are two ways to log in to SciServer
- With a SciServer account
- With a linked Globus account
To log in with SciServer
- At the Login page, under the Login with SciServer section, enter your username and password
- Click the Sign in button to access your account, and you will be taken to the SciServer Dashboard:
- JHU JHED ID
- Gmail
- OrcID
Technical Note: This is achieved using the external support of Globus Auth, by creating a (separate) link between Globus and each of the above accounts, then linking that to the SciServer Account.
How do I log in with my organizational account?
- Click the Sign in with Globus button.
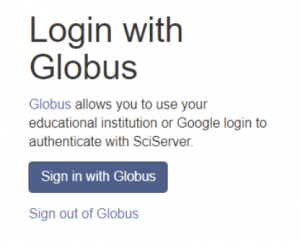
Note: If you have previously linked your external account(s) to your SciServer account, proceed to the Sign In step below. If not, follow the rest of the instructions to enable the link.
- Choose the organization you belong to from the dropdown menu
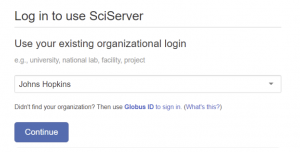
If you do not see your organization listed in the dropdown menu, you can log in directly through Globus.
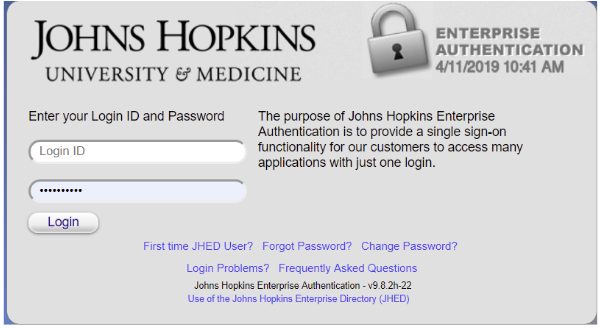
- Press the Continue button, which will take to the authentication system for your organization
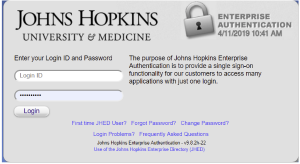
- Enter your organizational credentials and log in; you will be returned to the SciServer login control
- Advanced: If you are re-linking an account, you may sometimes get a Globus Auth message as follows:
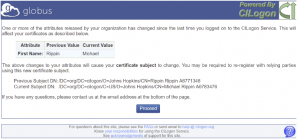
- Simply press Proceed to get to the SciServer screen.
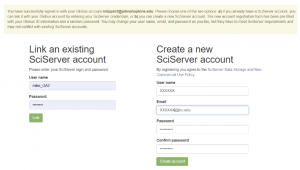
- After the Organization Account Linking, at the SciServer screen you are presented with two options:
- Link the organization account to an existing SciServer account
- Create a brand new SciServer account
Both options are described below.


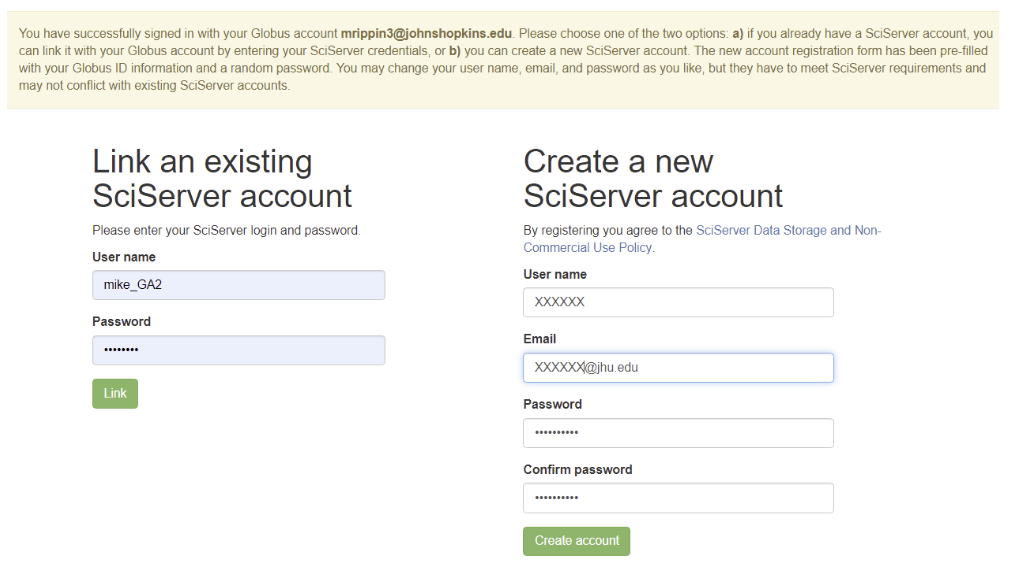
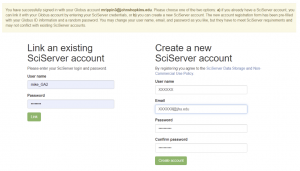
Link an existing SciServer account
- Simply enter the username and password and press the Link button
- This will both link the two accounts (your organizational credentials and your existing SciServer account)
- You will be redirected to your SciServer dashboard home page
Create an new SciServer account
- SciServer will pre-populate all fields to create a new SciServer account for you, based on the Orgainization account details you provided (username and email), and a random password
- You are free to change any and all of these fields (username, email and password)
- Press the “Create Account” button to link the two accounts
- You will be redirected to your SciServer dashboard home page
Sign In
- Once you have linked an external account to your SciServer account by following the steps above, you can subsequently log in to SciServer by entering your external account into (rather than your SciServer credentials)
- On the SciServer login portal home page (https://apps.sciserver.org/login-portal), click the Sign in with Globus button
- This will take you to the page where you can pick which linked account to sign in with – to use an organizational account, select your organization from the dropdown menu:
- Click Continue and you will be taken straight to your SciServer Dashboard home page:
How do I log in with my Gmail account?
-
- Click the Sign in with Globus button
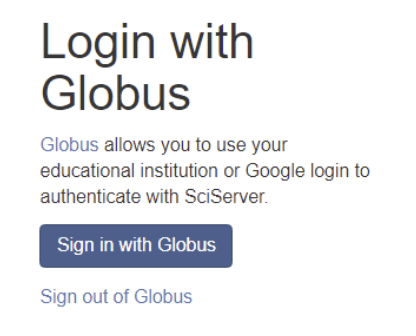
- At the next screen, click the Sign in with Google button
- You will then follow the same steps for Account Linking and Logging as for
Organizational linking as described in section How do I log in with my organizational account?, except you will be taken to the Gmail login page to enter your account credentials.
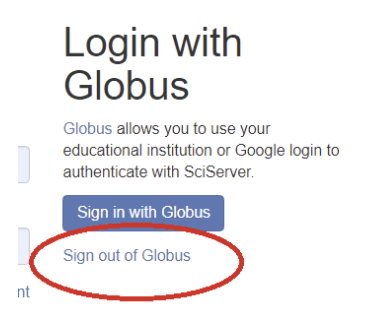
If you log in to SciServer through an external account (for example, a university account or a Gmail account), logging out of SciServer will log you out of SciServer only, and will not log you out of the external account. You may continue to use the external account in other applications.
SciServer provides a separate link to log you out of the external account as well, should you wish to:
Simply click the Sign out of Globus link to log out of the external account that you have associated with SciServer.
If you have linked your SciServer account to an external account (e.g. an organization, Gmail, or ORCiD), you can later unlink it by doing the following:
-
- Log in to the appropriate SciServer Account from the login portal
- From the SciServer Dashboard menu, select My Account
-
- This will show a pop-up dialog box with options down the left-hand side. Choose Manage Linked Globus Accounts.
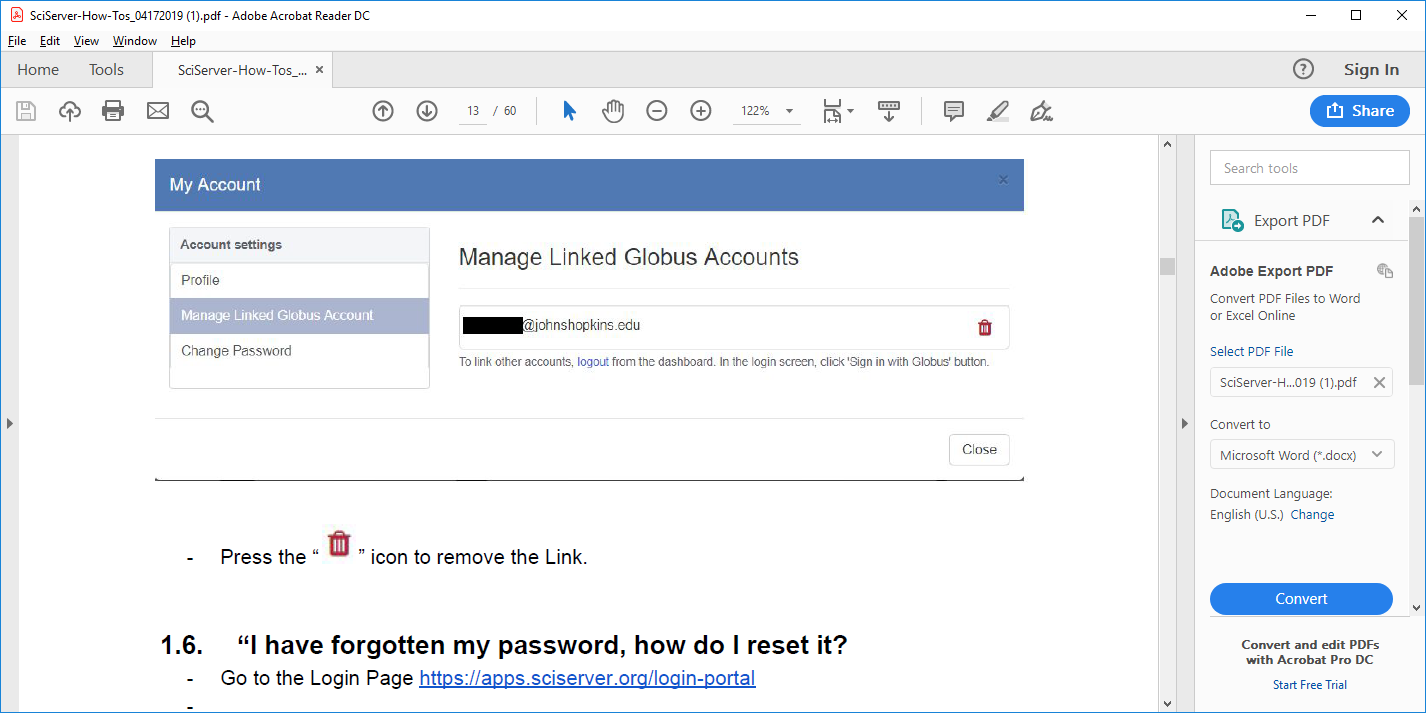
- Click on the trash can icon to unlink your external account

-
- From the SciServer home page, click the Login to SciServer button
- A new page opens containing the SciServer Login Portal
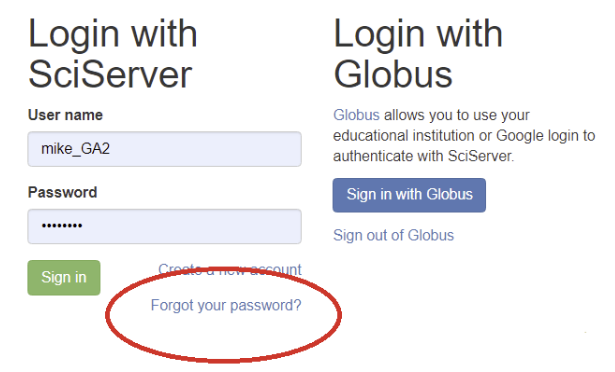
-
- Click the Forgot your password? link to go to the Reset Password page:
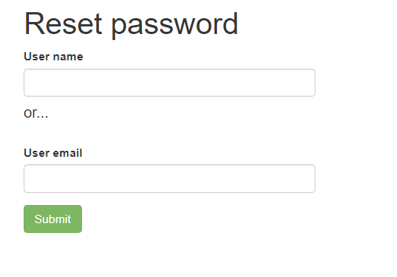
-
- Enter either your username or your email address, then press Submit.
- This will send an email to the address you specified when you registered
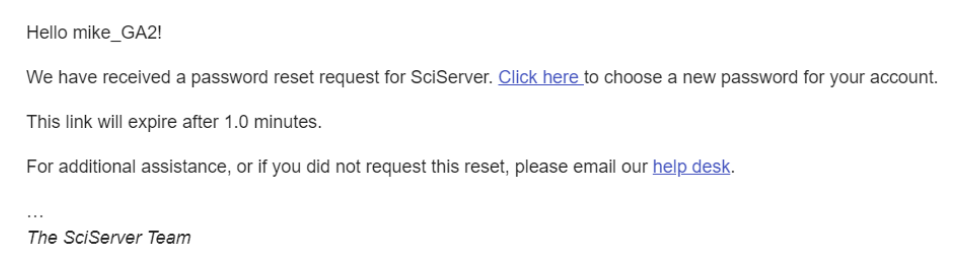
-
- Press the Click here link in the email, and you will redirected to enter your new password:
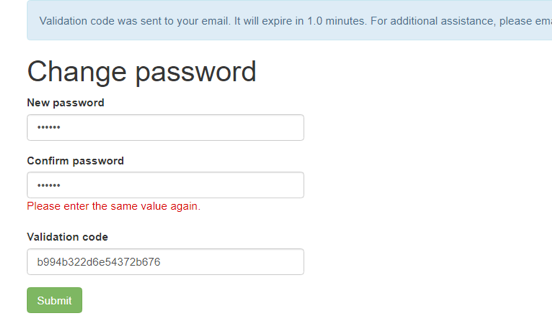
- Click the Submit button and your password will be reset
-
- Go to the SciServer Dashboard:
-
- Access the Menu in the top right-hand side corner:
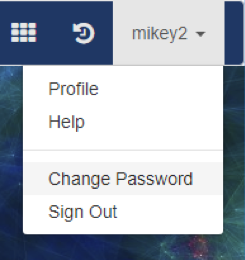
-
- Select Change Password which will display the Change Password dialog box:

-
- You can also select My Account, then Change Password
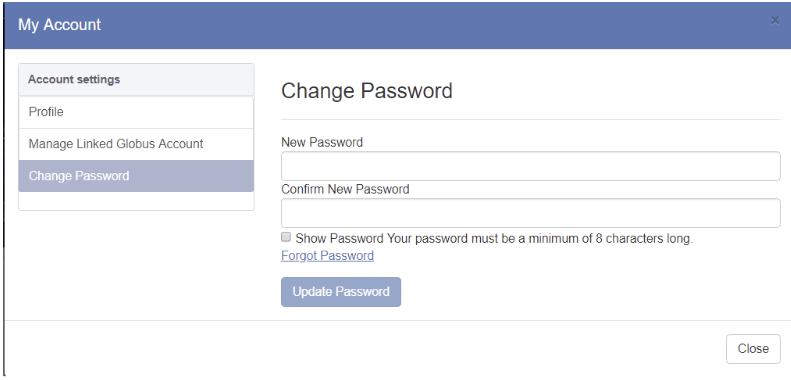
-
- Enter your new password (twice) and press the Update Password button
- This will change your password, and then display a message that you will be redirected to the Login Page to re-login
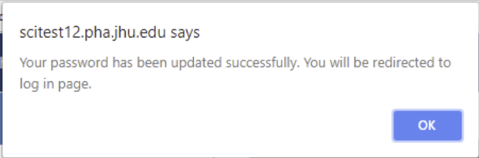
- You will then need to re-login using your new password to access your account again
-
- Access the Menu in the top right-hand corner of the SciServer Dashboard:
-
- Select “Help” to display a small dialog with a number of links:
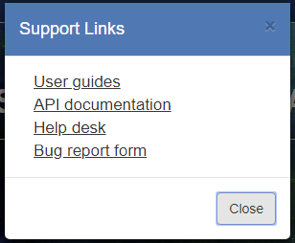
- Here you can find “User Guides”, “API Documentation” and “Help Desk”
-
- Access the Menu in the top right-hand corner of the SciServer Dashboard:
-
- Select “Help” to display a small dialog with a number of links:
-
- Here you can find “Bug Report Form”
- Select this and it will open a new Web Page on the sciserver.org website:

Small question mark icons can be found on most of the Dashboard pages with links to specific section of this How to Use SciServer document. The icons look like this:
![]()
Home Page
The Homepage for the Dashboard looks like this:
Menu and Functions
The Dashboard has a main “Menu Bar” across the top which is always visible in all views of the Dashboard, providing access to the following core features:
-
 Brings the user back to the Home Page
Brings the user back to the Home Page
-
 Navigates the User to a Tab to manage Files and Folders
Navigates the User to a Tab to manage Files and Folders
-
 Navigates the User to a Tab to manage user defined Groups and sharing
Navigates the User to a Tab to manage user defined Groups and sharing
-
 Displays a drop-down menu allowing the user to launch any of the supporting SciServer Applications (Home, Compute, Compute Jobs, CasJobs, SkyServer)
Displays a drop-down menu allowing the user to launch any of the supporting SciServer Applications (Home, Compute, Compute Jobs, CasJobs, SkyServer)
-
 Navigates the User to a tab displaying a tabular summary of the history of their activity with SciServer functions and applications
Navigates the User to a tab displaying a tabular summary of the history of their activity with SciServer functions and applications
 A Menu dropdown that displays additional options for the user (access Profile, Access Help, Change Password, Sign Out)
A Menu dropdown that displays additional options for the user (access Profile, Access Help, Change Password, Sign Out)
Function Shortcuts
A set of shortcuts are displayed to access the many functions in the Dashboard application itself:

In particular the User can access:
- Files
- Groups
- Compute Jobs
- Activity Logs
Each of these shortcuts also displays information about recent activity on, or notifications about, each function.
Application Shortcuts
A second row of shortcuts allows the user to launch any of SciServer’s core applications:

Each of these shortcuts will launch a separate web app in a separate Browser tab.
Note that “Compute Jobs” is in both shortcut lists.
If you have active notifications, the number of active notifications will appear next to the icon:  .
.
When you click on the Notifications icon, a panel will open from the right showing your active notifications:
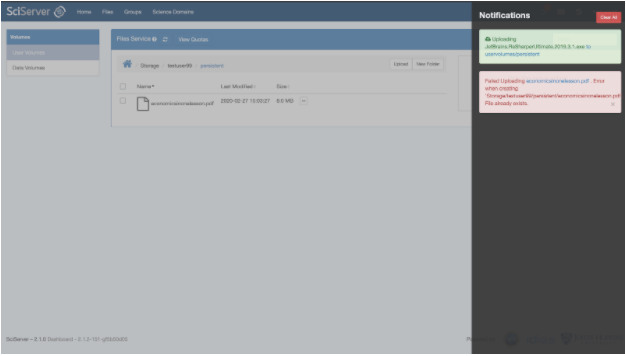
In the Notifications panel pictured above, green sections specify actions currently in progress, while red cards specify actions that have failed, along with their error messages. Once an action has completed, it will disappear from the list; once all actions have completed, a blue “No new notifications” message will display.
You can clear the notifications for any failed actions by clicking the ‘x’ at the bottom of the notification message. You can clear all notifications by clicking the red “Clear all” button at the top of the notifications panel. To hide the notifications panel, click on the dashboard outside the notifications panel space.
All notifications are cleared automatically when you log out of SciServer, or when you reload the dashboard page in your browser.
SciServer provides two ways to view your recent activities:
- The Dashboard displays the most recent activity related to File Management, Group Management, and Job Execution
- A separate “Activity View” accessible from the main Menu in the RHS corner provides a detailed table of all logged activities within SciServer, with filtering and sorting.
Dashboard Activity Summary
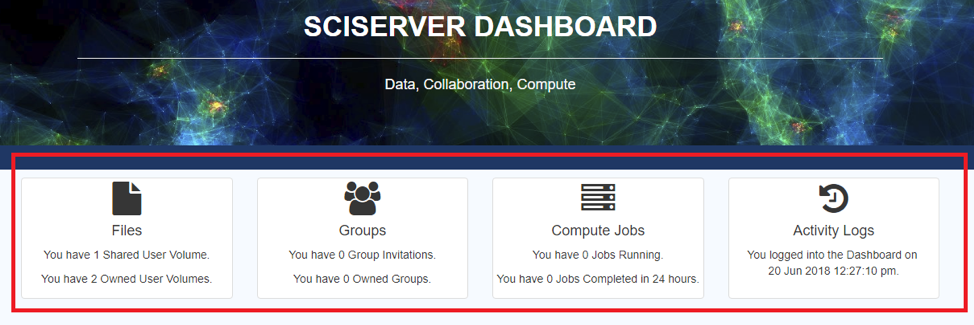
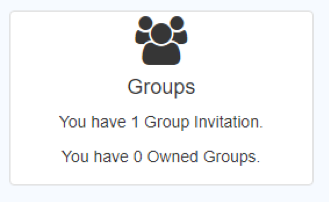
- On the main dashboard, a summary of Jobs, Groups and Files is provided as shown below
- In particular, Invites to new groups are shown, which the user can select to take them to the Groups tab in SciServer
Activity Log
-
- Access the top right-hand menu bar and click the Activity Log icon:
-
- This will display the Activities table:
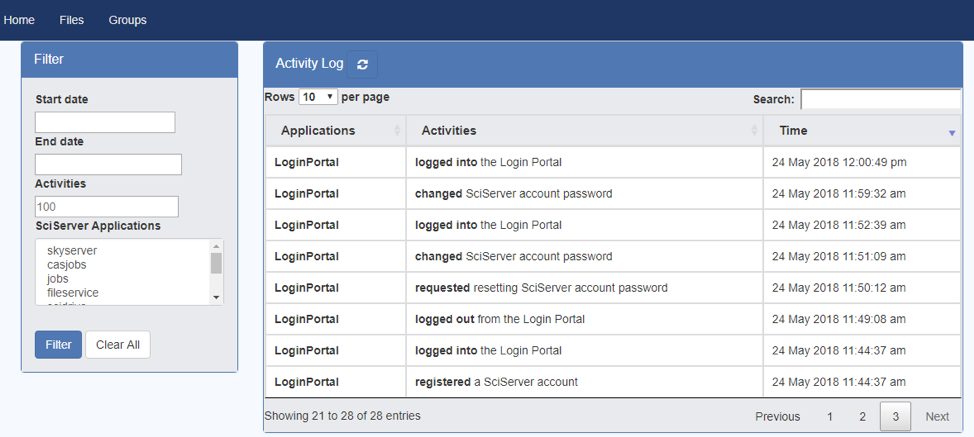
SciServer provides a feature called ‘Groups’ for users to share their resources with their collaborators privately. The resources that users can share are file folders, databases, volume containers, and Docker images. Also SciServer provides a Group view which lists all the shared resources among group members.
SciServer Groups allow you to create lists of Users and to share resources, such as file Folders, to all of them at once. You can manage a team of people in a project by creating a group with the relevant users in, and allowing everyone to work from the same shared folder. Importantly, you can also make sure that no one who is not in the group can access the shared folder, so you can keep things private.
-
- Select the Groups tab in SciServer
-
- This will show the Groups View

-
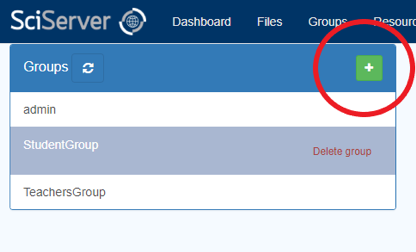
- The left hand box will show you all the groups that you are a member of. As you select each one, the middle set of boxes will show you which resources have been shared with that group, and the right hand box will show you all the members in the group.
- To Create a New Group, click the “+” button on the left-hand “Groups” box:
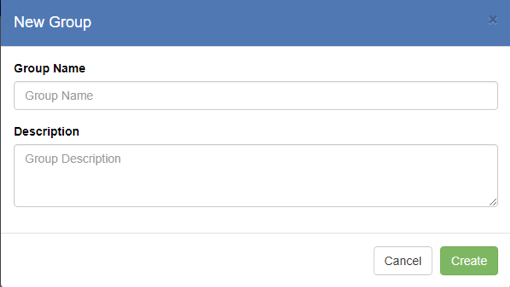
-
- This will open the “New Group” dialog box:
-
- Enter a name for the Group and an optional Description, then press the “Create” button. This will show your new Group in the “Groups” box, and will show you as the only member in the box on the right-hand side:
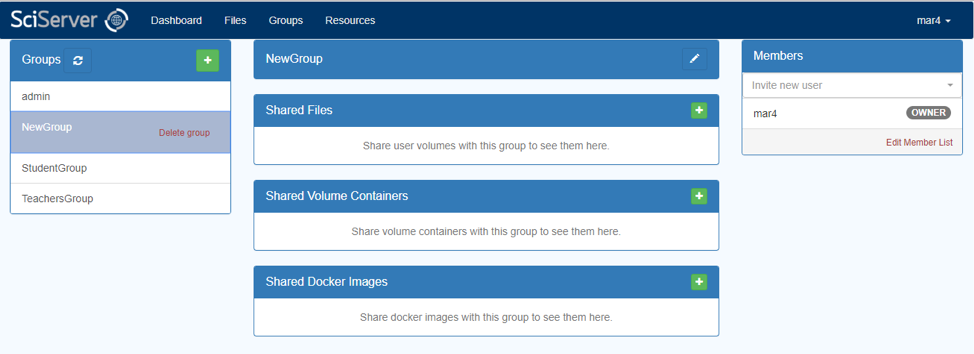
- This is your new group!
-
- You can invite other SciServer users only to groups that you own, or that someone else has given you the grant privilege on
- In the groups view, go to the “members” box on the right hand side:
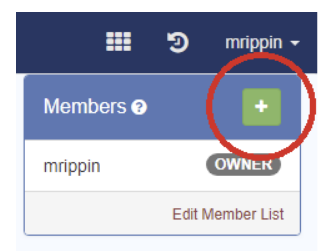
-
- Press the green “+” button to show the Add Members dialog box

-
- Select Users from the left hand panel. You can multi-select by holding down the “Ctrl” key and clicking on users. You can also search for users by typing characters into the Search box.
- Press the Invite User button:
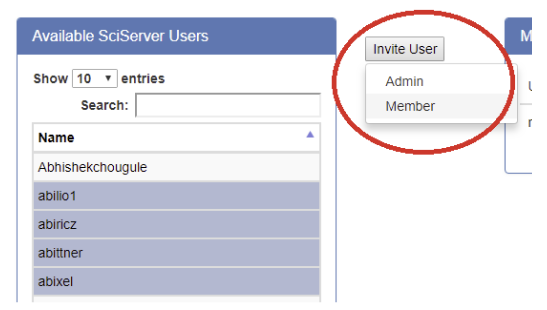
-
- You will need to choose “Admin”or “member”:
- Admin: means that this user will be able to invite other users to your group
- Member: means this user will not be able to invite other users to your group
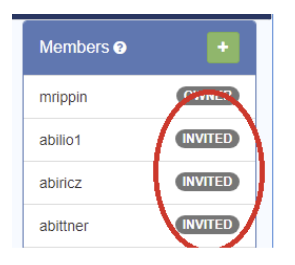
- This will add the users to your group with the status “Invited”
- You will need to choose “Admin”or “member”:
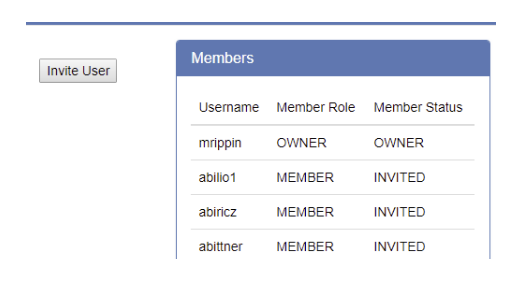
-
- Press the OK button in the lower right-hand corner to dismiss the dialog box
- NOTE: This will invite the users. They will need to accept the invitation before being a member of the group:
-
- On the Dashboard tab, you will see an Invite:
-
- Select the Groups tab, and you will see the Group listed with an icon next to it:

-
- Select the group and you will see an option to accept the invitation:
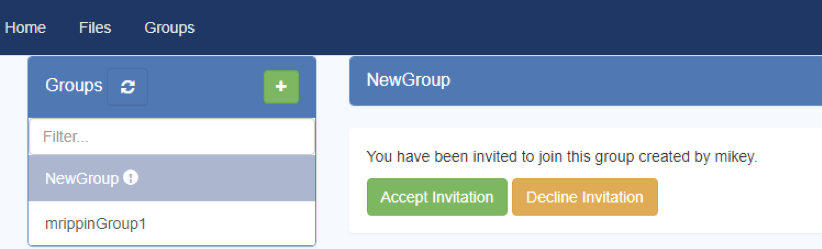
- Select “Accept Invitation”, and you will join the group and be able to access it.
-
- In the Groups Tab, selecting any of the groups on the left hand panel will show the resources already shared with that group. Resources that can be shared are: (1) File Folders (2) Compute Docker Images (3) Compute Volume Containers (4) Databases (in some circumstances). It will only show each box if there are any resources that you are able to share.
- Each of these resources is shared in a separate box, and each has a
 button
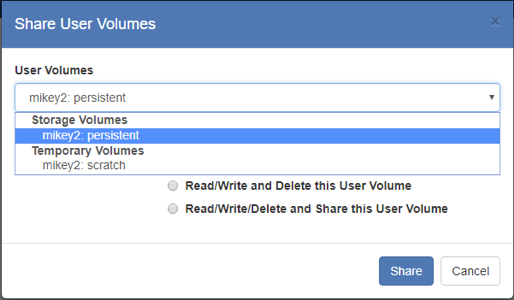
button - Clicking the button will display a dialog box where you can select resources that you have access to:
-
- Select the resource and permission level, then press “Share” and the resource will appear in the group:
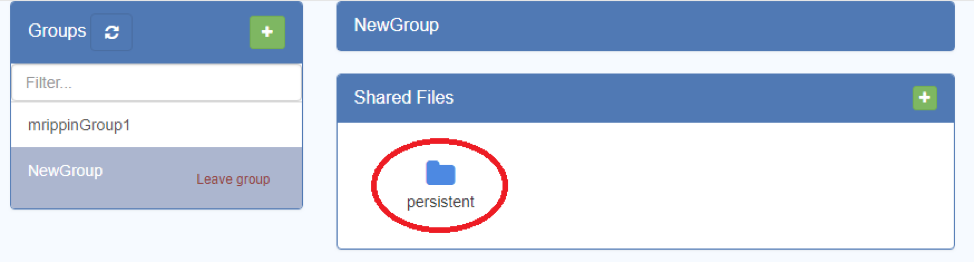
-
- In the Groups Tab, selecting any of the groups on the left hand panel will show the resources already shared with that group.
- Click on the shared resource
- Click “Remove”
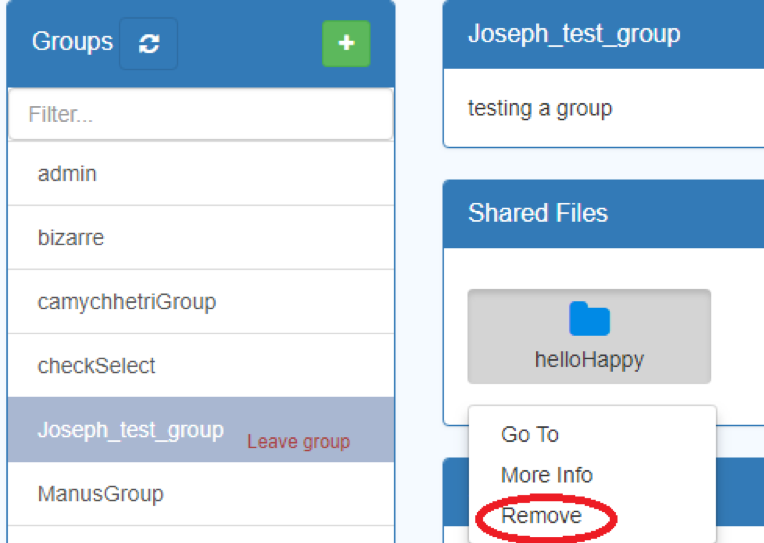
- An alert box will appear asking you to confirm deletion
- Click OK to proceed
-
- In the Groups Tab, selecting any of the groups on the left hand panel will show the resources already shared with that group.
- Click on the shared resource
- Click “More Info”
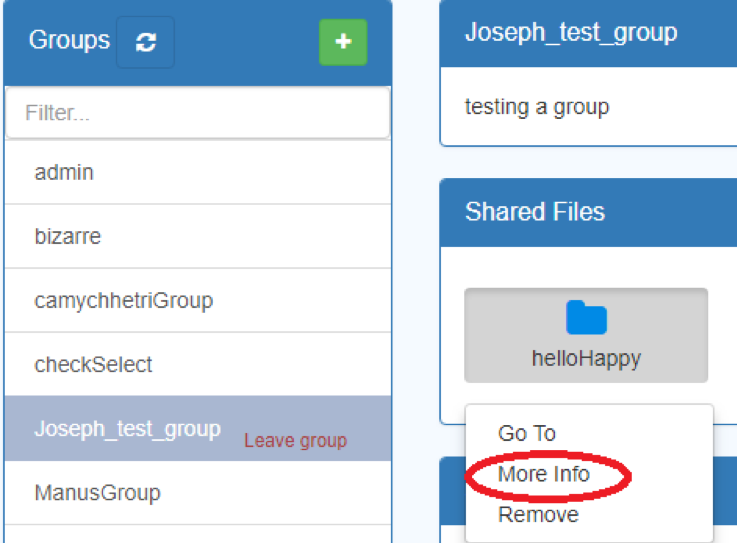
-
- Pressing this will display a dialog box where you will find more information:
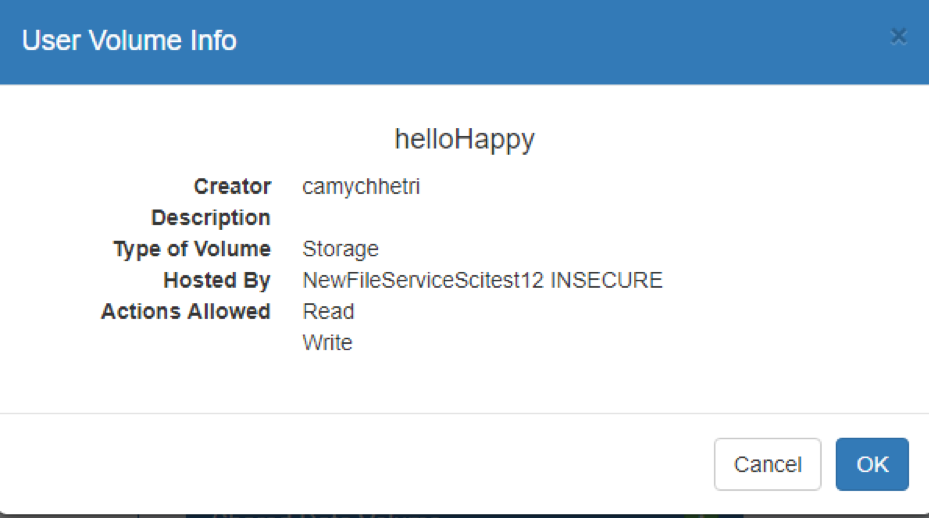
NOTE: the File Management features provided in the SciServer UI are different to the services provided by SciDrive, which is an older storage system that is still supported for legacy applications.
User Volumes and Data Volumes
SciServer supports two different types of file volumes:
- User Volumes: These are created and owned by individual SciServer users
- Data Volumes: These are institutional or organizational data repositories that are currently owned and managed by the SciServer system. In some cases, a SciServer user who originally provided the dataset in the first place can be made an owner and given administrative rights, and may grant teams of other users read-write access to their Data Volume(s).Otherwise, Data Volumes are public (all SciServer users can see them), and read-only to all users. For those users familiar with SciServer Compute, Data Volumes are the same storage volumes as the “Volume Containers” made available in Compute.

NOTE: This section of the Help documentation (“File Management: User Volumes”) will deal only with User Volumes. Data Volumes will be covered separately in the next major section (“File Management: Data Volumes”).
Permanent or Temporary Storage?
Users can create a number of top level “User Volumes,” under which new folders and files may be added. User Volumes can be created in one of two different storage pools: a permanent pool called Storage and a short-lived pool called Temporary.
Folders and files in User Volumes under Storage will be backed up and permanent, but there is a quota limit of 10GB. Folders and files in User Volumes under Temporary are not backed up, and will be deleted after a particular time period, but there is no imposed limit or quota on how much data can be stored (because it will be deleted).
Most users should store their data and files in a Storage User Volume. The Temporary User Volumes are meant to be used as intermediate storage for SciServer Compute calculations.
-
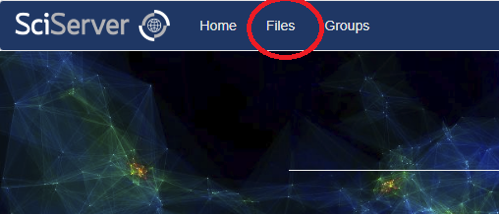
- Login to the SciServer dashboard and select the “Files” tab:
-
- This will show the Files View at the top level of “User Volumes”:
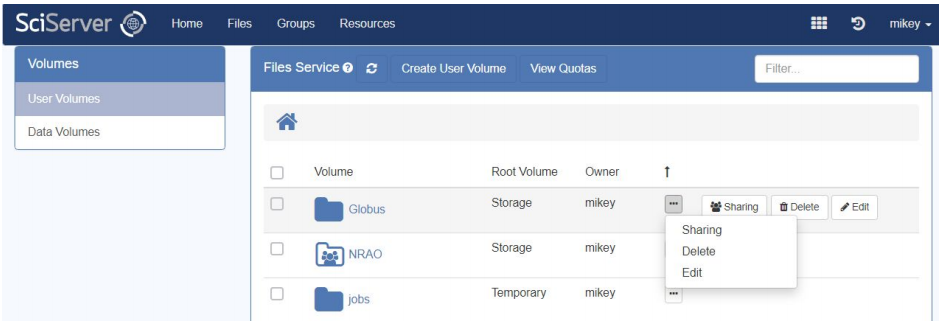
- NEW: Volumes and files are sortable! By default, Volumes are sorted alphabetically by volume name. Within a volume, files are sorted alphabetically by file name. You can change the sort order by clicking on the column header (e.g. Volume, Root Volume, etc.) Click on the same column header again to sort in descending order.
- There are a number of User Volume operations available in this view
- Hover over each row to view available operations
- Click on the ellipsis button to view available operations:
- Share: If the user has the appropriate permissions, they can share a User Volume with other users, or groups of users. A User Volume created by the user is always shareable by them.
- Delete: If the user has the appropriate permissions, they can delete a User Volume. A user can always delete a User Volume they create.
- Edit: The User Volume name can be changed, and a description provided for it.
- Different icons refer to different levels of sharing:
-
 This User Volume is owned by the user, and has not been shared
This User Volume is owned by the user, and has not been shared
-
 This User Volume is not owned by the user, but has been shared with the user by another user or group.
This User Volume is not owned by the user, but has been shared with the user by another user or group.
-
 This User Volume is owned by the user, but has been shared with another user or group.
This User Volume is owned by the user, but has been shared with another user or group.
-
- Selecting a Folder in the column on the left-hand side will open that folder up, one level at a time. It does not provide a tree view.
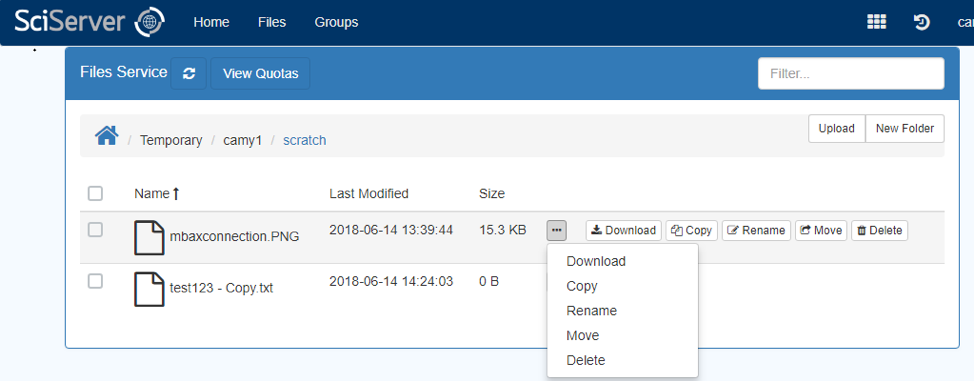
- This will show the Files View at the top level of “User Volumes”:
-
- There are a number of file and folder operations available in this view
- Hover on each to view available operations
- Click on the ellipsis button to view available operations
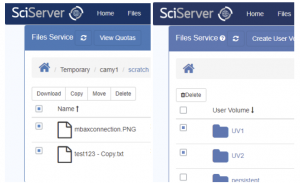
- Copy
- Rename
- Move
- Delete
- Download: A file can be downloaded (but a Folder cannot)
- Perform multiple operations on files or folders, or on User Volumes (currently only for the Delete operation):
- Check one or multiple checkboxes
- The menu gets displayed with available operations on top
- Click on any menu item to perform an operation
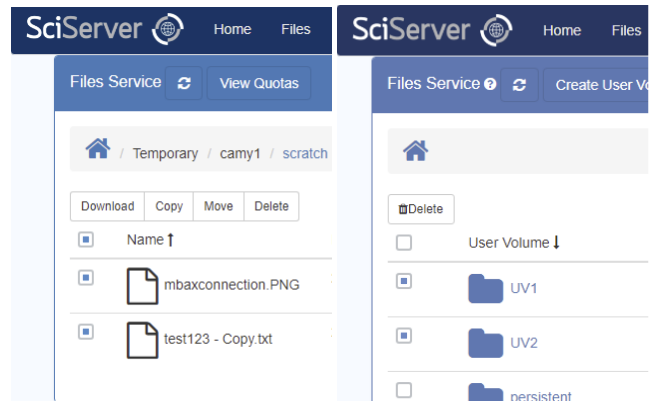
- When running SciServer Compute, the same filesystem is presented by the Jupyter application, but is presented in a more traditional hierarchical manner with a full path access that supports working with files in a Linux Console:

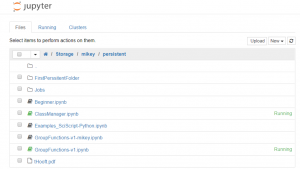
- The operations on files and folders available in this view are provided by Jupyter.

- There is only the one top level of User Volumes, all subsequent lower levels are normal Folders
- A User Volume can be shared with others users and groups, but a normal folder cannot. This is very important.
- A User Volume can be selectively “mounted” in a Compute Container, and made accessible to a Jupyter Notebook. Folders at lower levels under a Volume Container cannot be.
- A User Volume cannot be moved or copied.
-
- On the SciServer “Files” tab, click the “View Quotas” button:
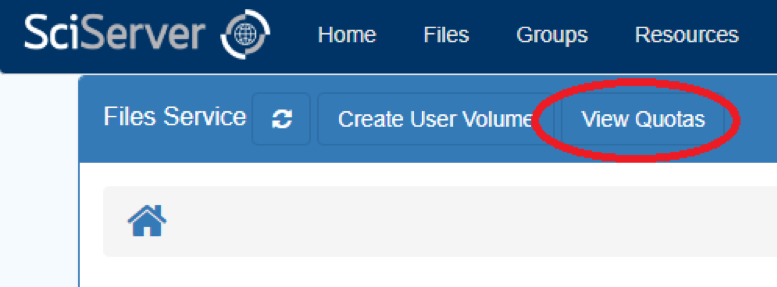
- The “View Quotas” dialog box appears
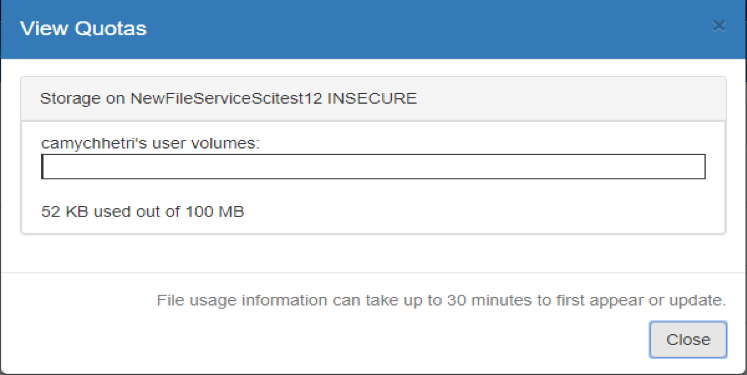
-
- On the SciServer Files tab, click the
 button to get back to the User Volume view:
button to get back to the User Volume view:
- On the SciServer Files tab, click the
-
- Press the “Create User Volume” button:

-
- In the dialog that pops up, enter a name and optional description:
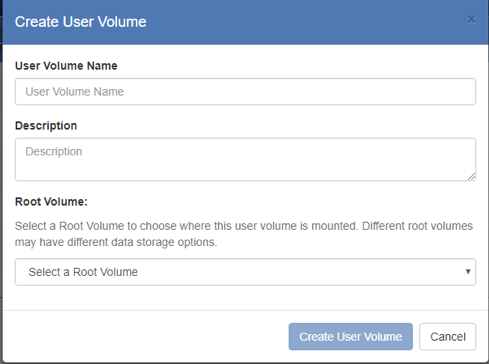
-
- Select a “Root Volume,” which means decide whether to create the new User Volume in a permanent and backed-up Storage pool, or to create it in a Temporary pool, knowing that it will be deleted after a certain period of time (defined by the SciServer Data Storage Policy).
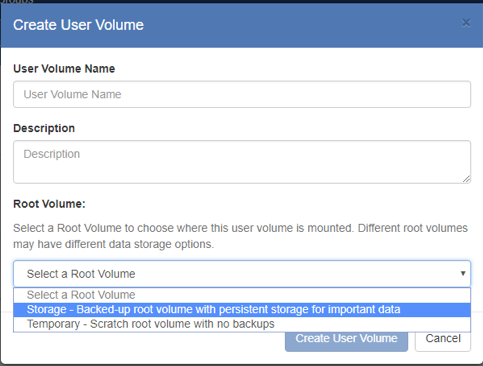
- Press the Create User Volume button and the new User Volume will be created.
Files cannot be uploaded directly to the top-level User Volume level.
Files can be uploaded to any Folder inside an existing User Volume, including in that User Volume’s top-level directory.
Upload Files using the Upload Button
-
- Navigate into a User Volume and you will see an “Upload” button:
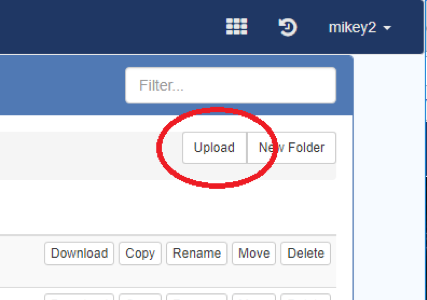
-
- Press the Upload button to display a dialog box:
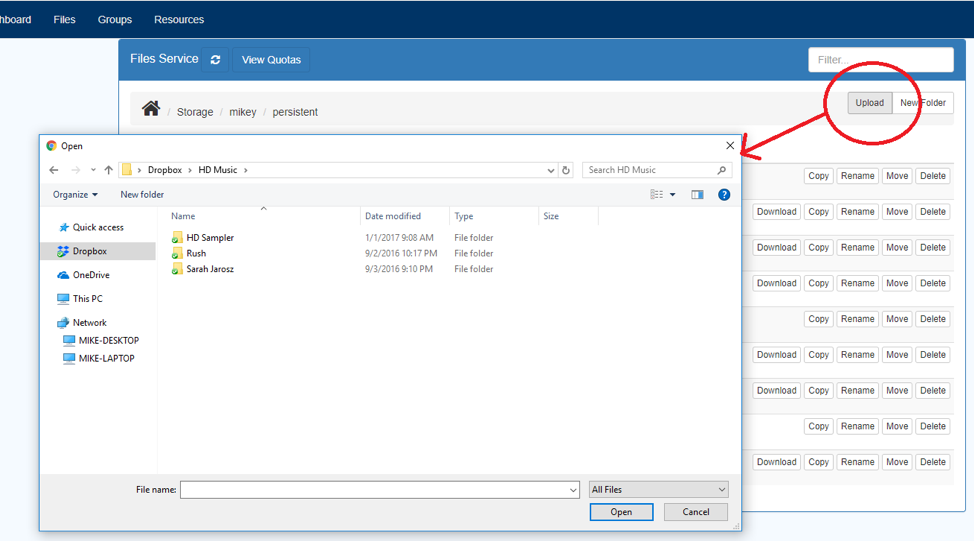
-
- You must navigate to a File, select it then press the “Open” button
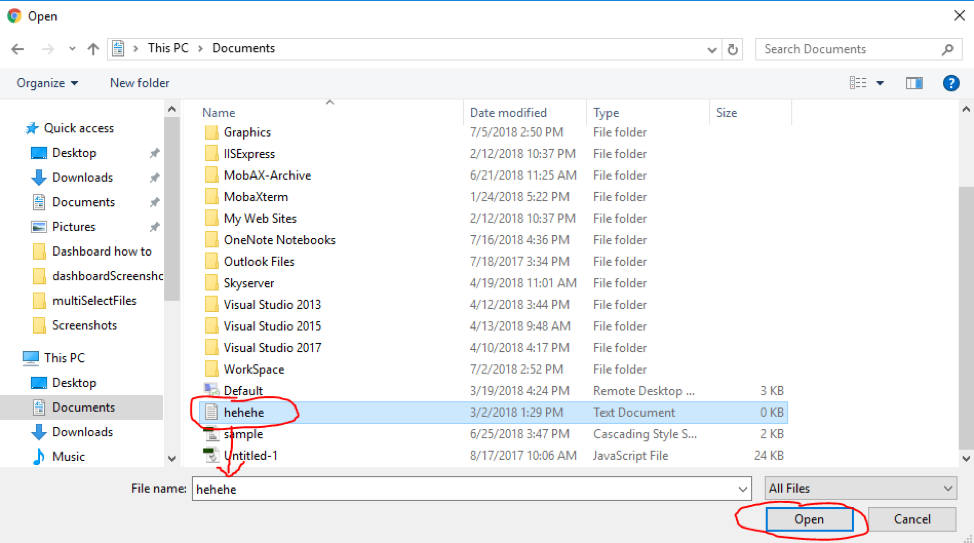
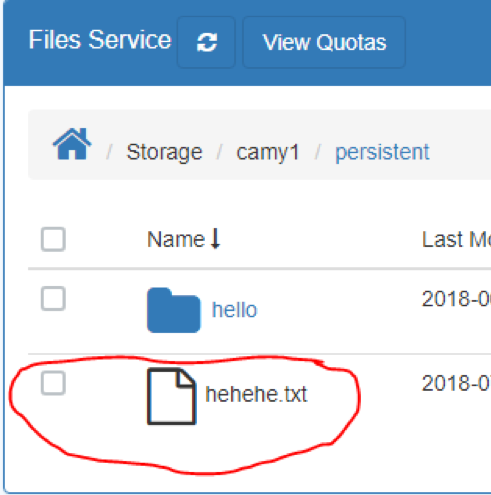
-
- This will then show the file you just uploaded:
Upload Files using Drag and Drop
-
- At the User Folder level (not Root folder level), the files view displays a “Drag and Drop” box
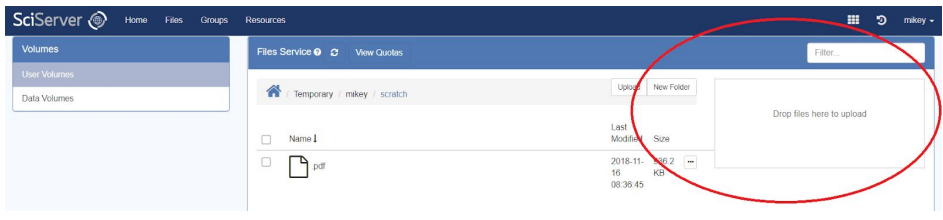
-
- You can drag and drop multiple files from, say, Windows Explorer, onto this box, and they will be uploaded to the displayed subfolder
- Upload progress is displayed
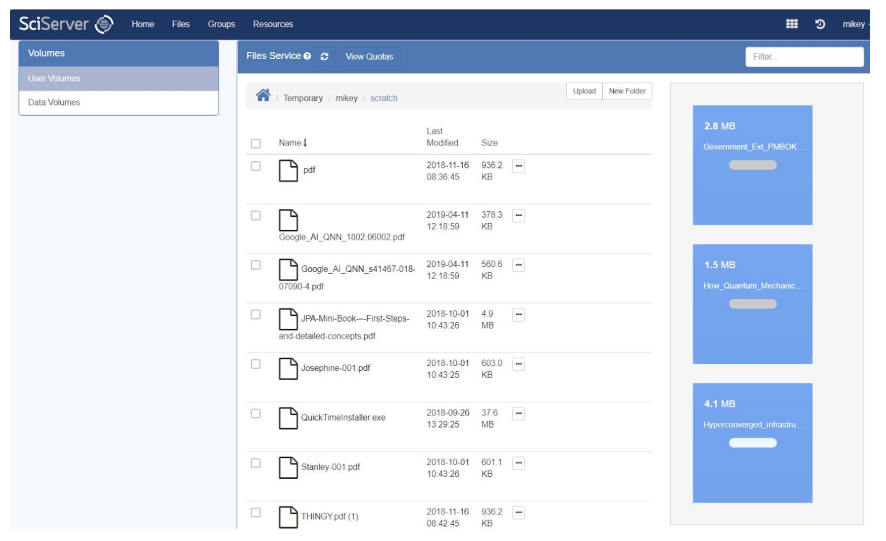
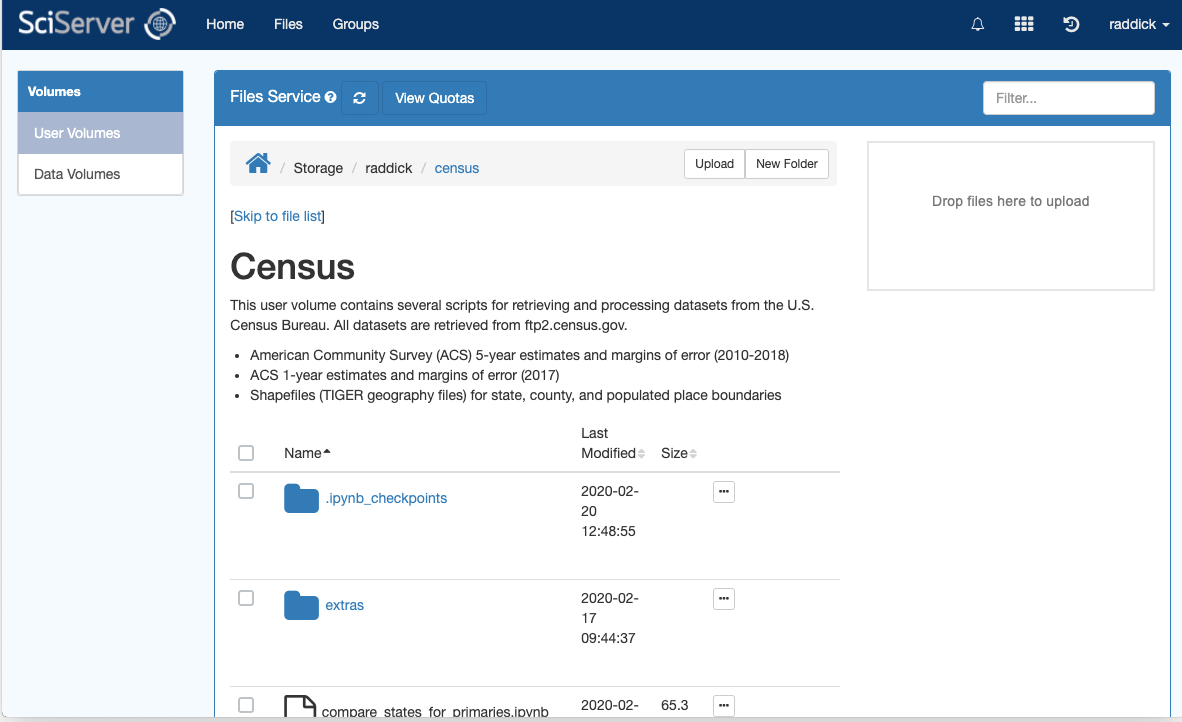
Like GitHub, SciServer allows you to upload a file called README.md offering a high-level introduction to the purpose, contents, and structure of your User Volume. Adding a README.md file makes it much easier for your colleagues and others to understand your data.
The name is case-sensitive; README must be in all capitals and the file extension must be lowercase: README.md
When you upload a README.md file into a User Volume, SciServer will automatically render the file and display its formatted text at the top of the page, as shown in the image below. You can click on the “Skip to file list” link to jump down the page to the list of files.
If you delete the README.md file from your user volume, this extra information will disappear.
-
- You can share any User Volume that you own, and you can share others’ User Volumes if they assigned you that permission when they shared it with you
- On the SciServer Files tab, click the button to get back to the User Volume view. You will see a list of User Volumes. All User Volumes that you are allowed to share will have a Sharing button next to them:
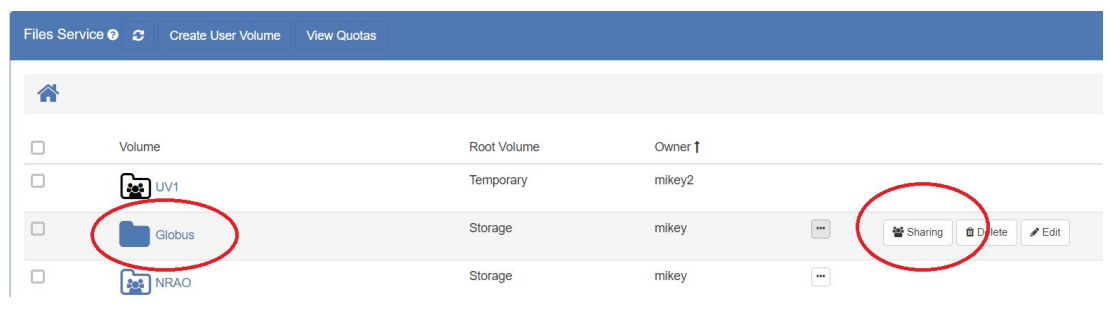
-
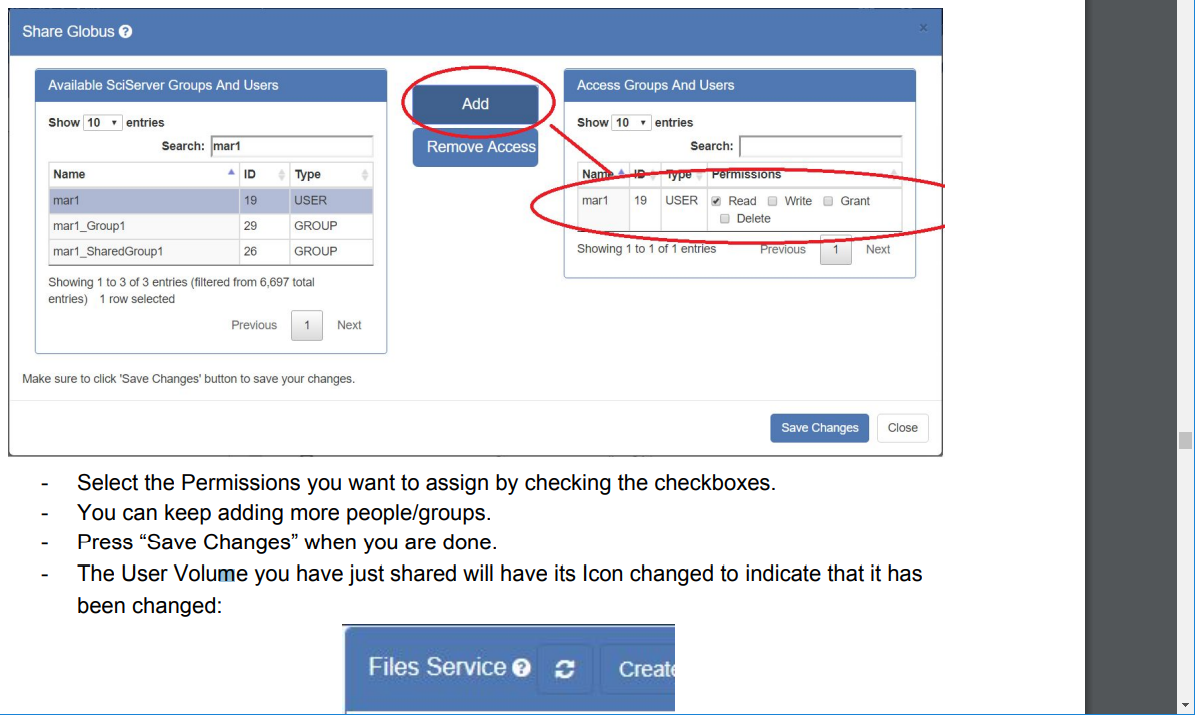
- Click the “Sharing” button and it will display a pop up dialog box:
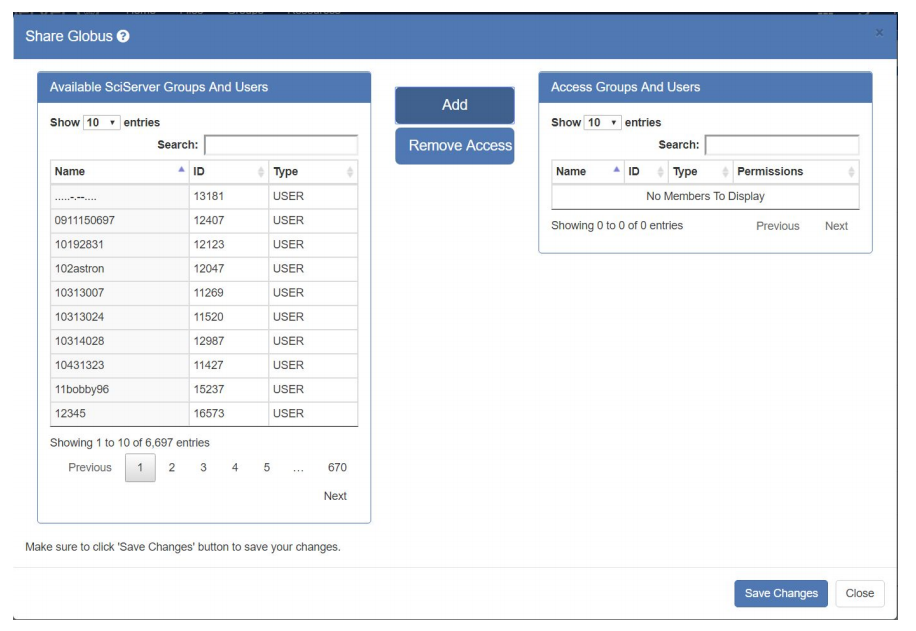
-
- The left hand panel is where you choose, one at a time, the users, or groups of users, that you wish to share with. To find users more easily, type something in the “Search:” box and the list will be filtered:
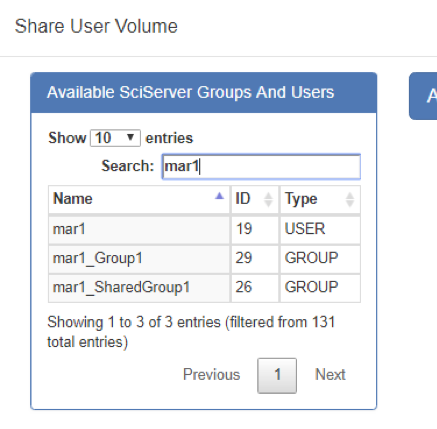
-
- Click on the name you want to add to the group to highlight it, then press the “Add” button:
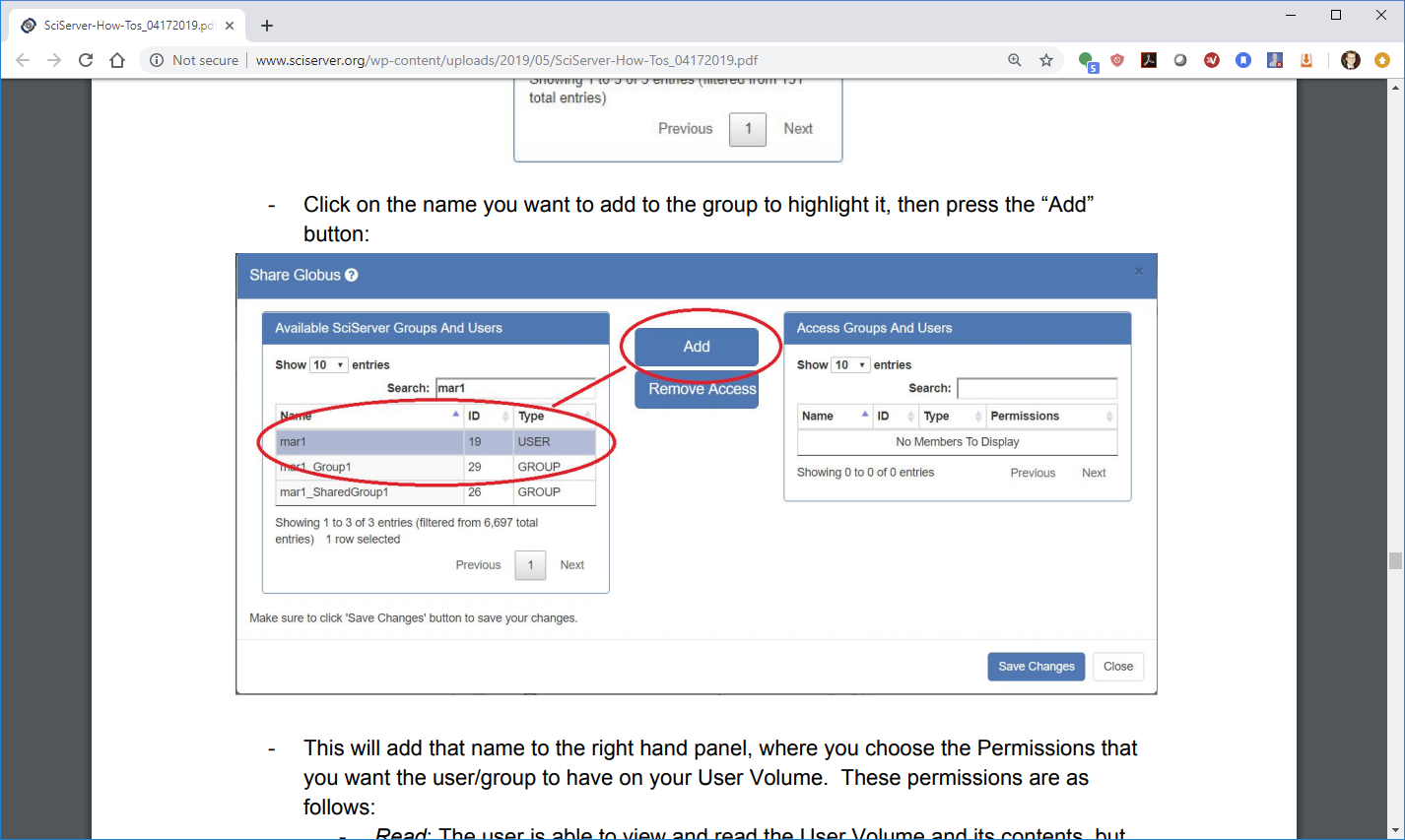
-
- This will add that name to the right hand panel, where you choose the Permissions that you want the user/group to have on your User Volume. These permissions are as follows:
- Read: The user is able to view and read the User Volume and its contents, but not change anything
- Write: The user is able to write new files and folders to the User Volume
- Delete: The user is able to delete the User Volume (not recommended!)
- Grant: The user has the ability to also further Share this User Volume with other users.
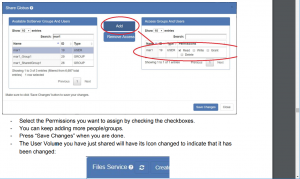
- Select the Permissions you want to assign by checking the checkboxes.
- You can keep adding more people/groups.
- Press “Save Changes” when you are done.
- The User Volume you have just shared will have its Icon changed to indicate that its sharing permissions have been changed:
- This will add that name to the right hand panel, where you choose the Permissions that you want the user/group to have on your User Volume. These permissions are as follows:
The process for Unsharing is the same as sharing described in the section How do I share a User Volume?.
- At the Files tab, click the button to get to the top-level User Volume view, and you will see the list of User Volumes. All User Volumes that you are allowed to share will have a “Sharing” button next to them:
- Click the “Sharing” button and it will display a pop up dialog box:
- On the right hand panel, select the user you wish to Unshare with

- Press the “Remove Access” button OR just uncheck all the checkboxes manually
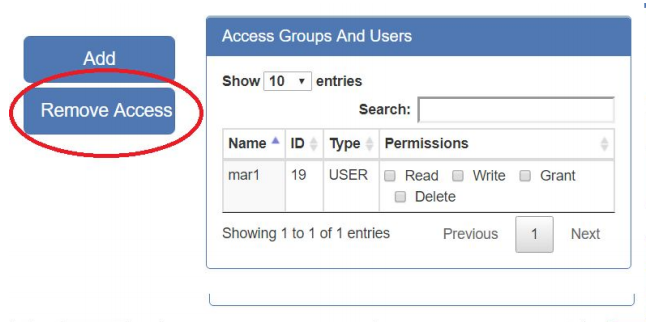
- Press Save Changes, and the User Volume will be displayed with the regular blue folder icon indicating that it is no longer shared
-
- Regular folder OR user volume that has not been shared
-
 User volume that has been shared BY you
User volume that has been shared BY you
- User volume (owned by another user) that another SciServer user has shared WITH you
To move or copy files between folders in SciServer, use the Files tab in the SciServer Dashboard:
- Select the Files tab
- Navigate to the files that need to be copied – hover the mouse over the file to show the “icons” (one of which is Copy, and one of which is Move). If you wish to move or copy are multiple files, select them all using the checkboxes, and select the “Copy” or “Move” button that appears at the top:
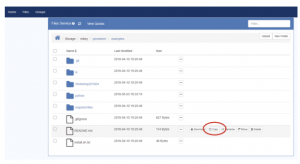
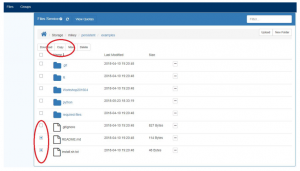
- When you press the Copy or Move button (in either of the above cases), this dialog will appear:
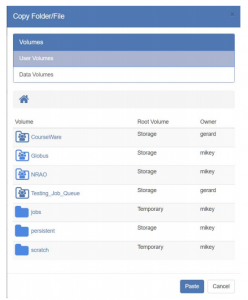
- Navigate to where you want to copy or move the files, and then press the “Paste” button:
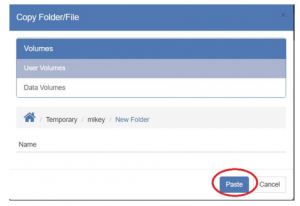

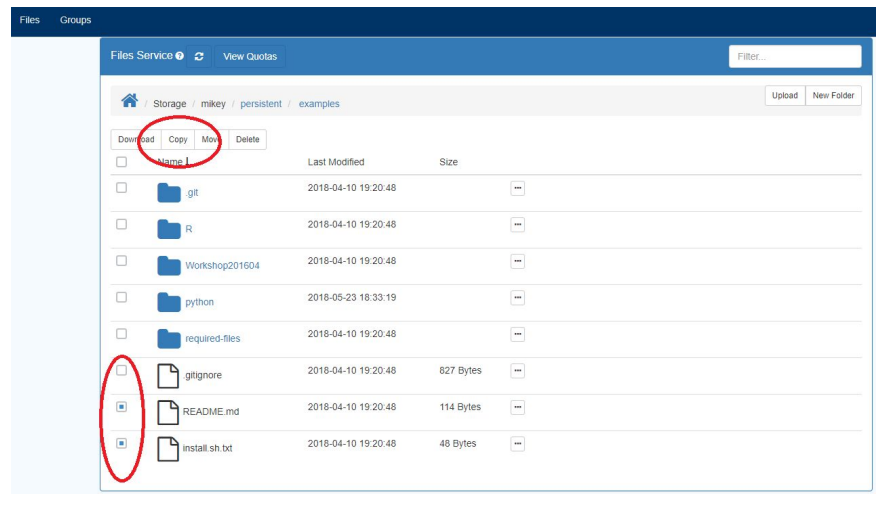
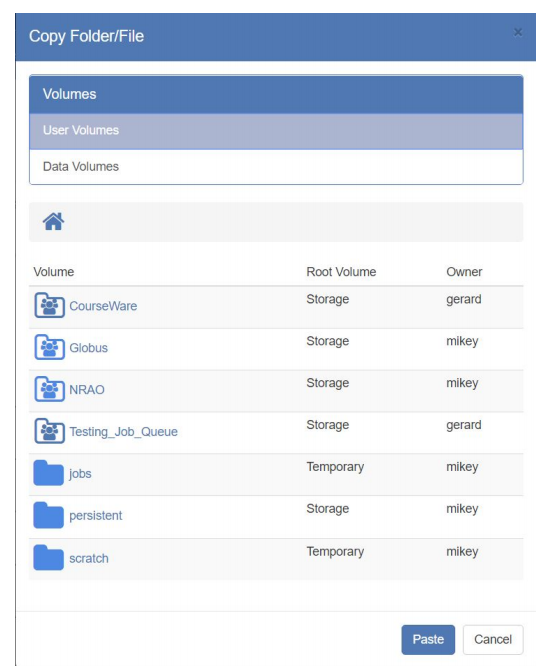
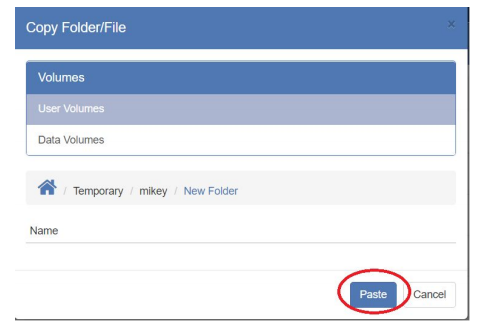
NOTE: You must have write permissions on the destination folder in order to move/copy a file or folder there
Some of the Data Volumes belonging to Johns Hopkins University are public, and all SciServer users will see them. Data Volumes are not part of any given user’s quota, though a particular user can be given the “owner” role by JHU Admin staff for them to subsequently share their data volume with particular users in their team or domain. A good example of a Data Volume is the Sloan Digital Sky Survey (SDSS) Data Archive Server (DAS) data.
The datasets were exposed as Volume Containers in SciServer Compute early on in the SciServer project to support the growing number of projects that needed to do analysis on the data. Now, exposing the datasets through the dashboard as data volumes makes it easier to quickly find out what datasets you are allowed to see, to view their contents, and to copy data from them to your own personal storage space. For some data volumes you may be granted write access, in which case you can add new data to a Data Volume from your SciServer dashboard.
- Access the Files view from the SciServer dashboard:
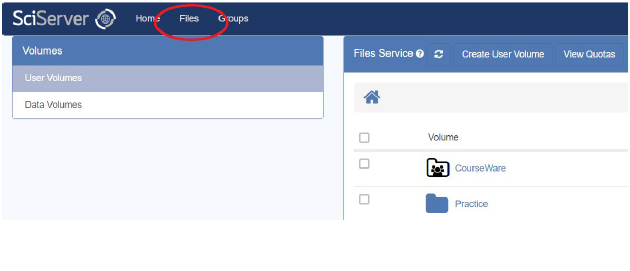
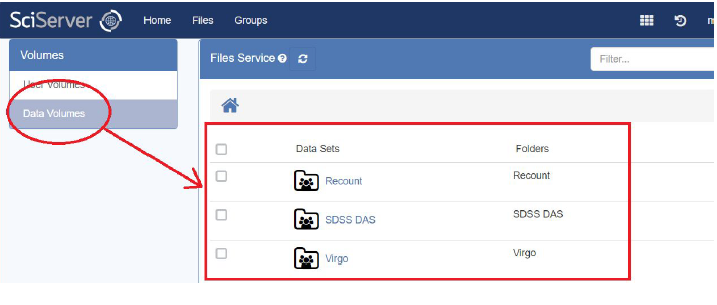
- You will see two options on the left-hand side: User Volumes and Data Volumes
- Pick Data Volumes and this will change the RHS view to display those data volumes that you have been given permission to see:
- First, note that you can only copy data and/or folders from within a Data Volume, you cannot copy an entire Data Volume
- Inside a Data Volume of interest, navigate to the folder or file you want to copy – you will see an option on the right-hand side to “Copy” the folder or file:
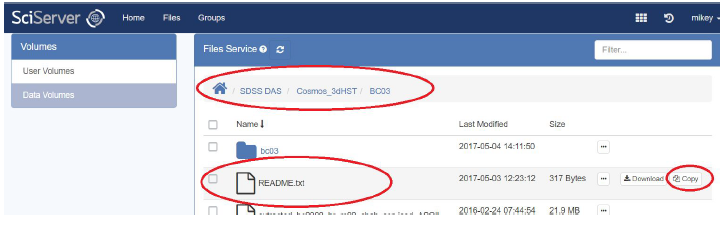
- Select the “Copy” button; this will show a pop up dialog where you can select where to copy the data to:
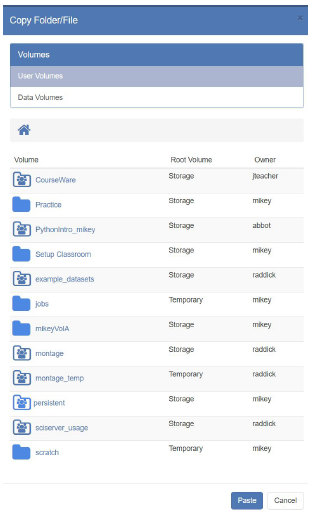
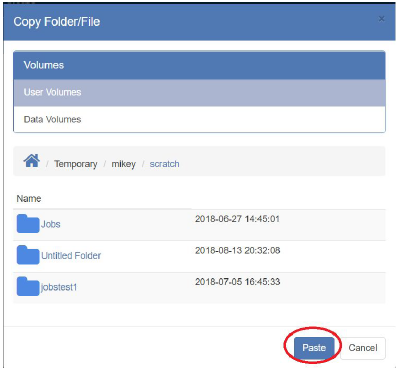
- Navigate to the directory of interest, and press the “Paste” Button:
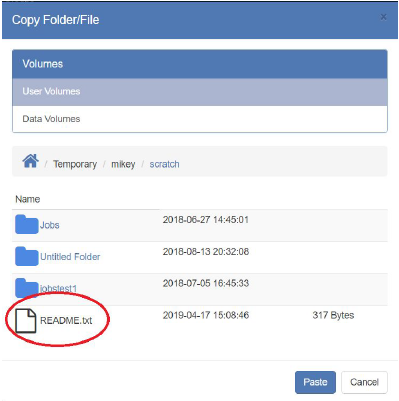
- The folder or file will now appear in the new place:
SciServer Compute is an application that allows users to easily create and run Jupyter Notebooks containing code and instructions to analyze and process SciServer hosted data sets. SciServer provides a rich API to access all aspects of SciServers resources, including databases, Filesystems, user and group management, and even Compute Jobs.
There are a couple of steps involved, which SciServer makes easy:
- Create a new “Container” to run the Jupyter Notebook in. A container defines the “environment” for the user, and is configurable
- Open the container, which will start Jupyter, and create, save and execute Notebooks.
- The full capabilities of Jupyter (which is a third party application) are available to the user and will not be covered here.
An important step in setting up a Container environment is specifying what external file systems will be accessible to the Jupyter environment.
A Container in SciServer Compute is a defined environment within which Jupyter Notebooks can be run. Its is technically a Docker Container (Docker is the technology used), and provides a way to isolate the user and their code from the rest of the SciServer system, and other users.
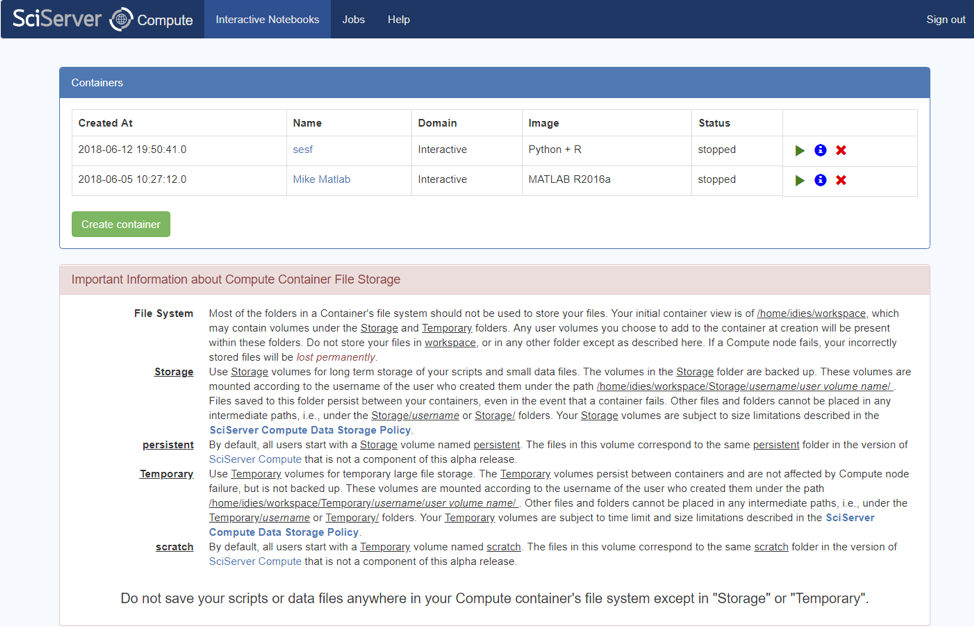
A Container in SciServer Compute is a “long-lived” resource, and as such there are some resource management issues you need to know about:
- Each User can create up to 3 containers at any given time. If you need another one, you need to delete one first.
- Containers have a lifecycle, and can be “running” or “stopped”. SciServer keeps Containers running for a certain period of time, even if the User is not actively working with it, to ensure that when a user comes back to it, it starts up nice and fast without delays.
- Running Containers consume system resources like memory etc., and run on an environment with inherent risk of failure. We do not make any guarantees on the lifetime of a container and they are subject to be terminated without notice. Any data stored on a container’s ephemeral filesystem (as opposed to user and data volumes) is subject to loss.
- Whereas data (files, folders) can be stored “in” the container, you should never do this for any data that you need to keep. Always store data files in the Storage or Temporary storage pools, which are external to the container. Data in these storage pools are accessible when all containers are closed or deleted, and the same data is accessible across any containers that includes those Volume Containers in their environment.
Creating a new Compute Container is easy! However there a few parameters required to define the compute environment that you need.
-
- Access the Compute Application by clicking on the “Compute” icon on the SciServer Dashboard:

- OR from the “Apps Menu”

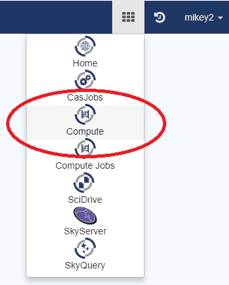
- Access the Compute Application by clicking on the “Compute” icon on the SciServer Dashboard:

- This will take you to the “Compute dashboard”
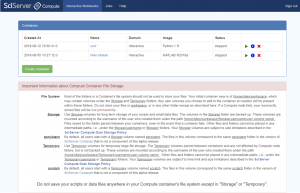
- You will see a large text box explaining how to use the Storage capabilities to ensure that you do not lose data if you accidentally store it in the Container itself.
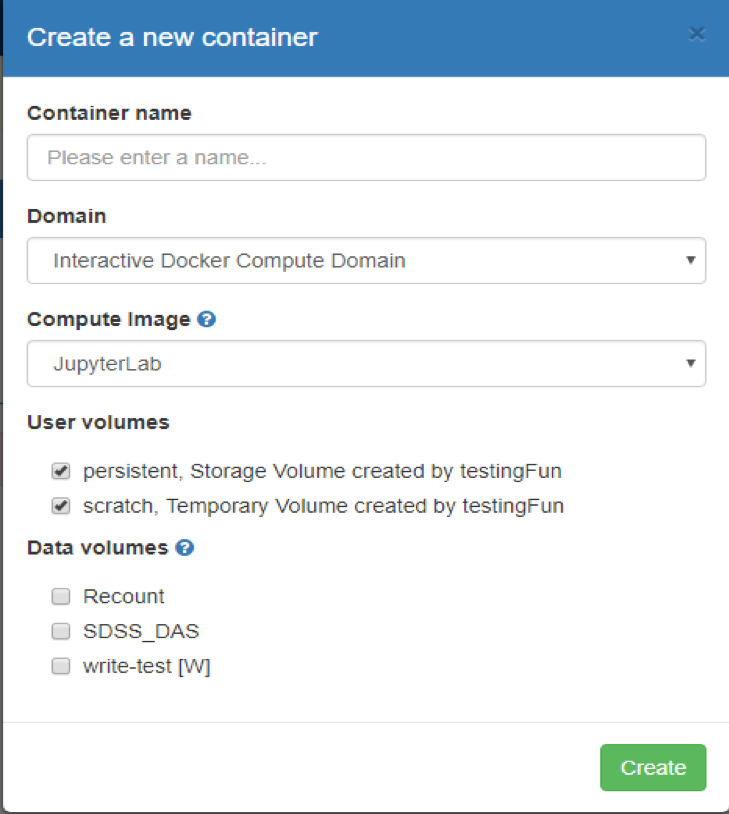
- Press the “Create Container” button, and this will pop a dialog box:
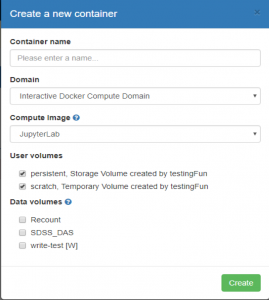
- The following needs to be entered:
- Container Name: you choose this
- Domain: This is a drop down from which you should most always leave at the default value “Interactive Docker Compute Domain”.
- Image: This define a “software environment” for the Jupyter notebooks that you want to run. The images contain libraries tailored to different needs. For the most part you will choose an image that supports the language you are interested in (python, R, Matlab etc), but there are “specialty” science domain specific images that you may have access to if the creator of those images has shared it with you. Additional information on “Images” can be found here at the Compute Images help page.
- User Volumes: This is a list of all User Volumes that you have access to, either which you own, or which have been shared with you. When you select some of these, on container creation these folders will be “mounted” and will be accessible as if they were local files. This makes file access and management much simpler. NOTE: they will be mounted with the same access controls as you would have in the SciServer File UI i.e. “readonly” or “readwrite”.
- Data Volumes: These are a series of special Data Volumes that are either shared publicly with all users, or for which you have been given special access privileges to see. Again, selecting these Volumes will mount them, and make them appear “local” in the Container. These will always be mounted “readonly”. Additional information on “Data Volumes” can be found at the Available Datasets page.
- Once created, it is not possible to add additional User Volumes or Data Volumes, so you should be sure to get this right.
- Pressing the “Create” button will create a new Container and show it in the table with the name you provided.
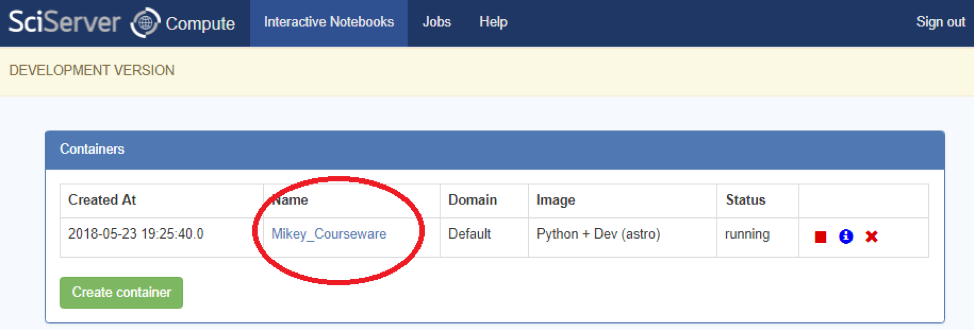
- Clicking on the link in the column titled “name” will launch Jupyter
-
- Start one of your Compute Containers to Launch Jupyter:
- A new window will open showing your filesystem, which is accessible through Compute.
- Navigate to the directory in which you want to create your notebook.
- Select New from the top right corner of the interface to open the dropdown menu
- Select the language that you would like the new notebook to use
- The notebook will open in a new window
-
- When you open a Container, Jupyter will start showing the files and folders, and you will see an option at the top to “switch To JupyterLab”:
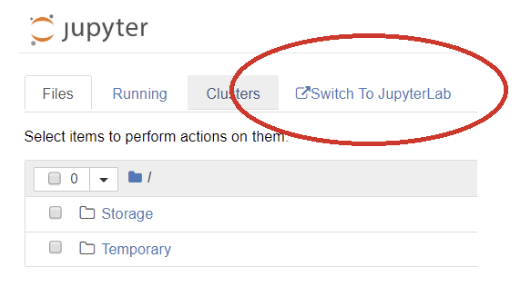
-
- Selecting this will put your Jupyter session:
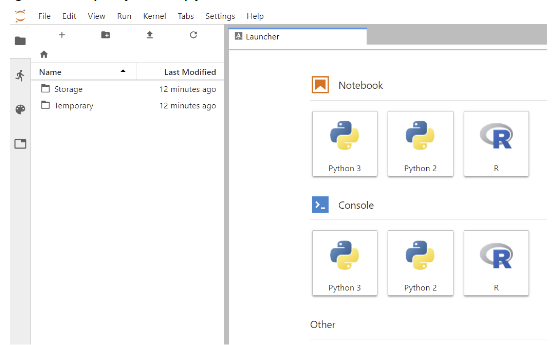
-
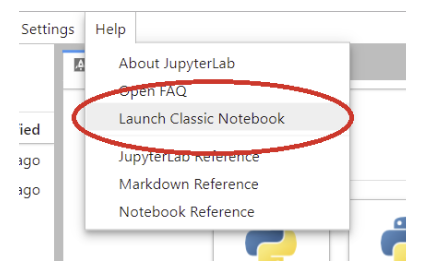
- To get back to “Classic Jupyter” view, select the menu item Help -> Launch Classic Notebook:
Compute Jobs allows a user to run a Jupyter Notebook or a standard script in offline batch mode. The same exact capabilities are provided as for Interactive Compute:
- Compute Images and software environment
- Mounting external volume folders
Executing a job will put it in a queue, and it will be run when there are resources available on the server cluster.
You might create a Job for the following reasons:
- Executing your notebook may take a long time and you want to set it running and do something else without worrying about browser sessions timing out etc.
- You may develop your code interactively to make sure the algorithm works, using a small amount of data to test it out. But you really want to run your code against a full dataset which will require massive resources for memory and CPU, as well as execution time.
- You are provided with far more resources (CPU and memory) to execute a Job than you are in an Interactive Session.
SciServer allows you to define two “types” of job:
- Specify a script to execute, or a command line command
- Specify an existing Jupyter Notebook that you have previously developed
The second of these is the most useful in that you can develop your Jupyter Notebook interactively then “submit” the exact same notebook as a Job.
Creating a new Job is easy! We explain how to create a notebook based job, but creating a script based job is very similar.
-
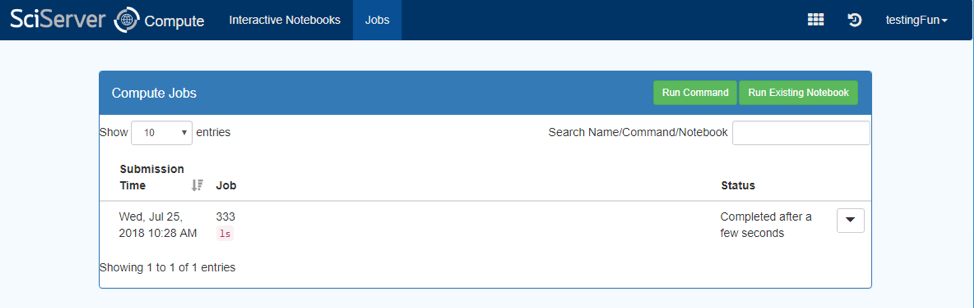
- Go to the Compute Jobs Page:
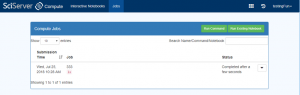
- Click “Run Existing Notebook”
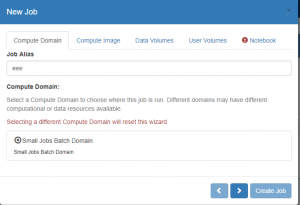
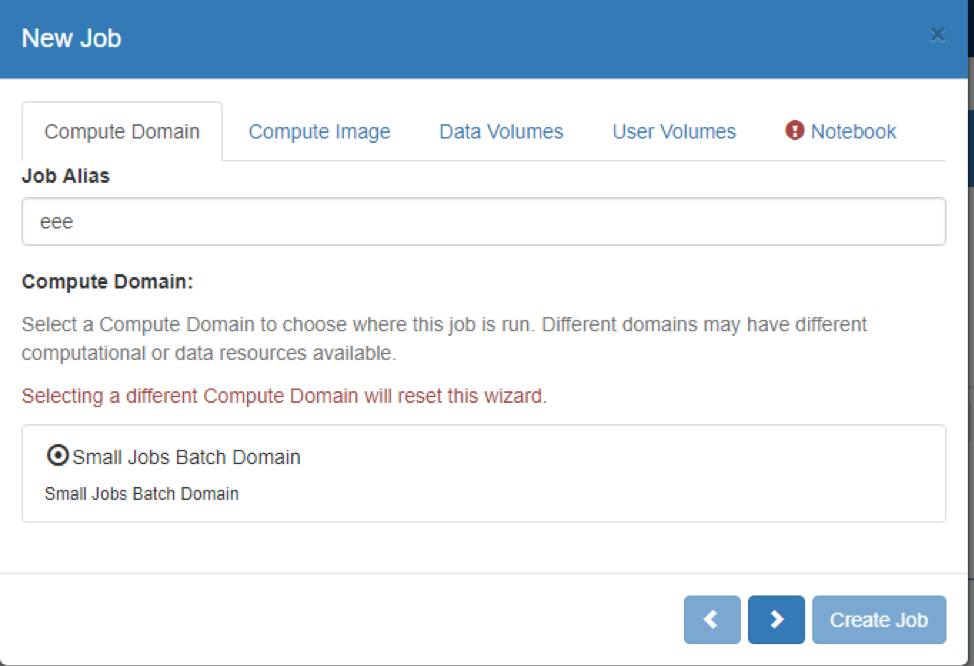
- On the ‘Compute Domain’ Tab:
- Choose the Compute Domain, for which in most cases currently there will only be one option
- Optionally enter a “Job Alias’ to easily identify your Job later
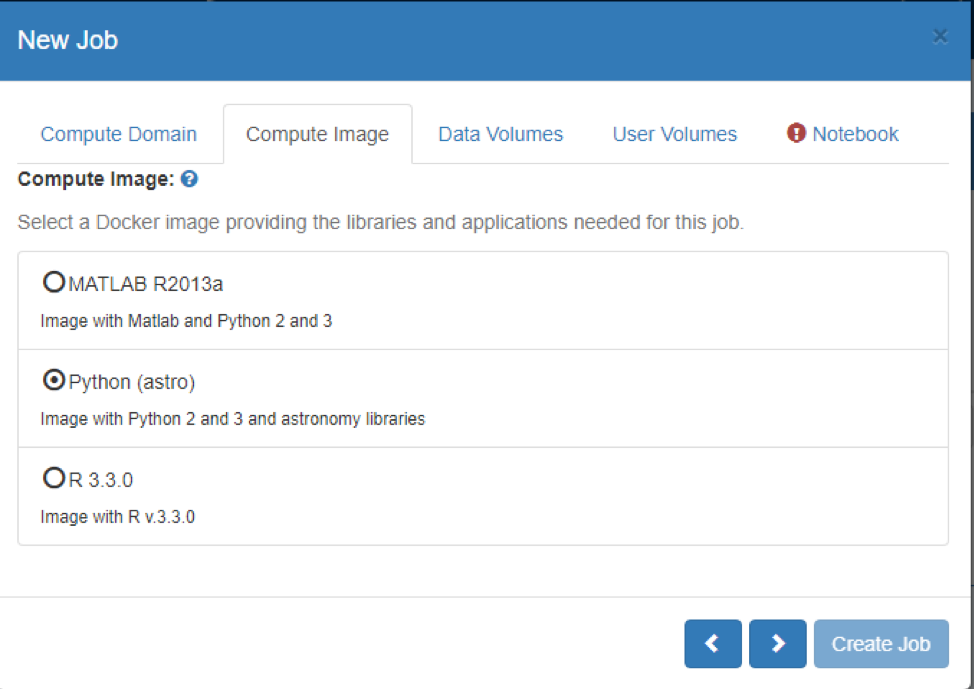
- On the ‘Compute Image’ Tab:
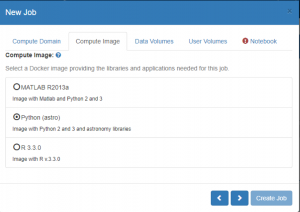
- Pick the ‘Image’ you need to use.
- Each image contains different tools and programming language support.
- (Compute Images are described in more detail at the Compute Images help page)
- Go to the Compute Jobs Page:
-
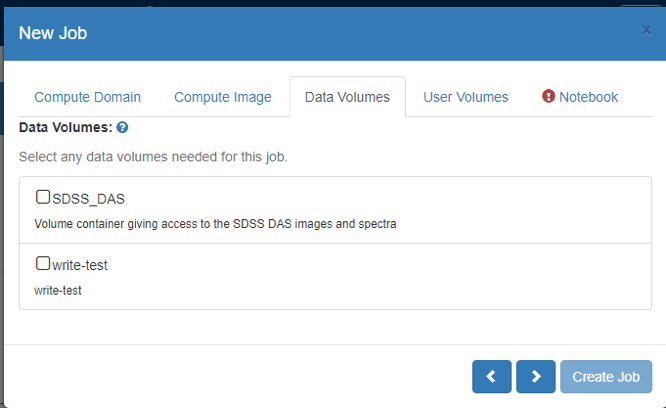
- On the ‘Data Volumes’ tab:
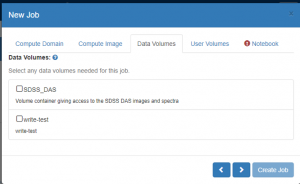
- Select all the data volumes with appropriate permissions needed for this job.
- On the ‘Data Volumes’ tab:
-
- On the ‘User Volumes’ Tab:
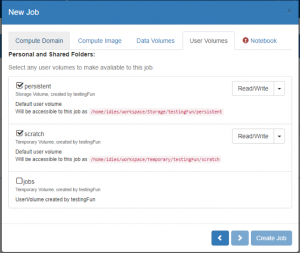
- Select all the Folder systems that you would like to be made accessible to your Compute notebook
- For Folders that you own, or that have been shared with you and you were given the appropriate permissions, you can select whether a given folder is read only or writable. Folders that you do not own will be readonly by default.
- On the ‘User Volumes’ Tab:

-
- On the ‘Notebook’ tab:
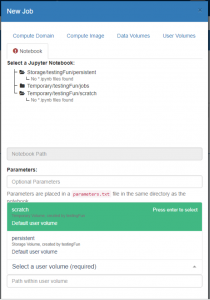
- Navigate to the Notebook you wish to use as the basis for your Job, and select it
- Enter any additional parameters that the Notebook can read in to affect how the code is executed
- Choose a directory where the output results will go
- By default these will go to jobs within which subdirectories will be created and your results written to.
- Alternatively you can choose a specific directory to output results. The directory you choose will be a ‘root’ within which subdirectories will be created and your results written to.
- On the ‘Notebook’ tab:
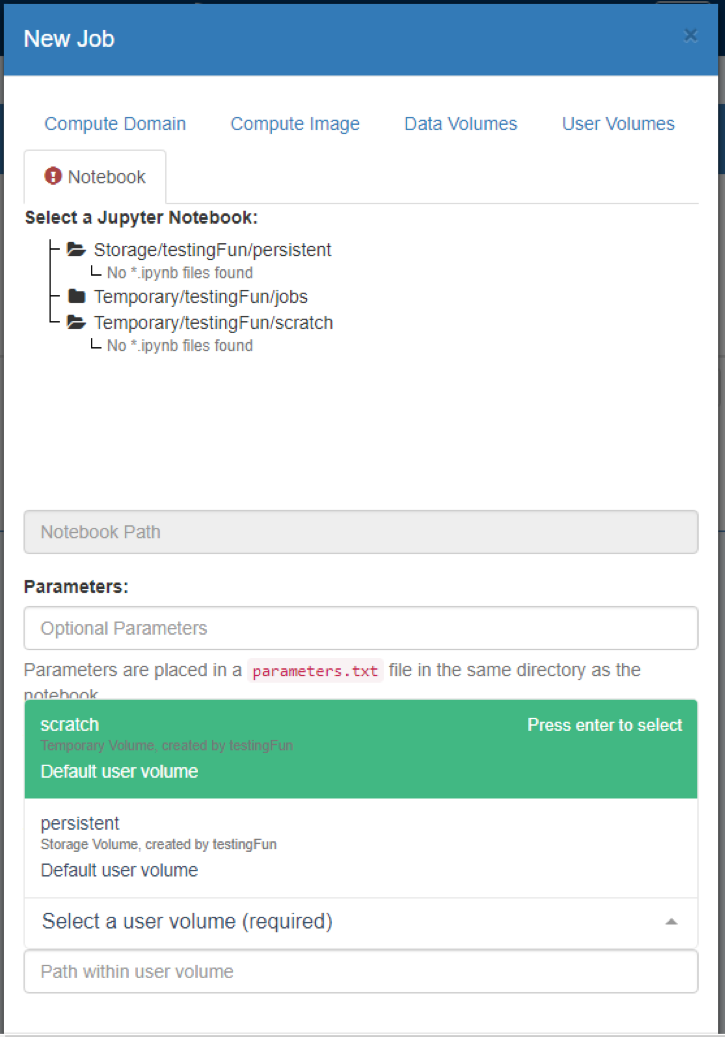
- When everything has been entered you can press ‘Create Job’, and the Job will be submitted, and displayed in a Jobs Table view:
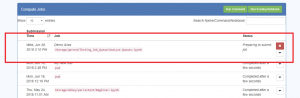
- The Table will be refreshed every several seconds, telling you the status of the Job.
- While the Job is still running there will be a red “X” button, and pressing this will Cancel the job.
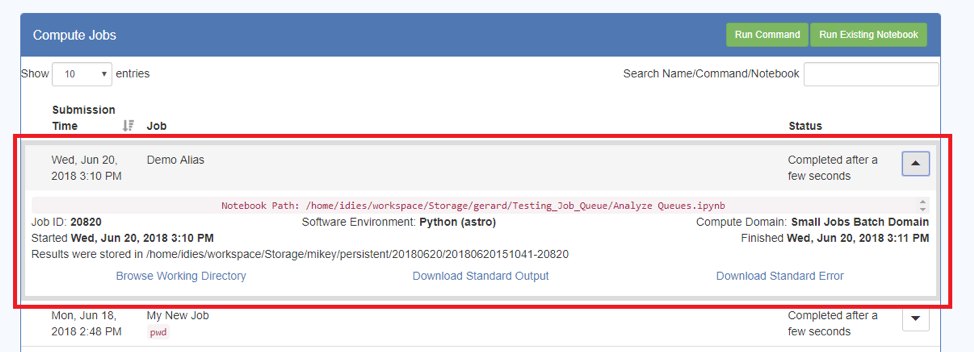
- Pressing the down triangle on the right-hand side will expand the view and show more information about the Job. This is what you see for a completed Job:
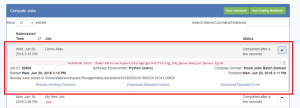
- This gives status information about the Job, the path to the location of the results, and links to the results output
-
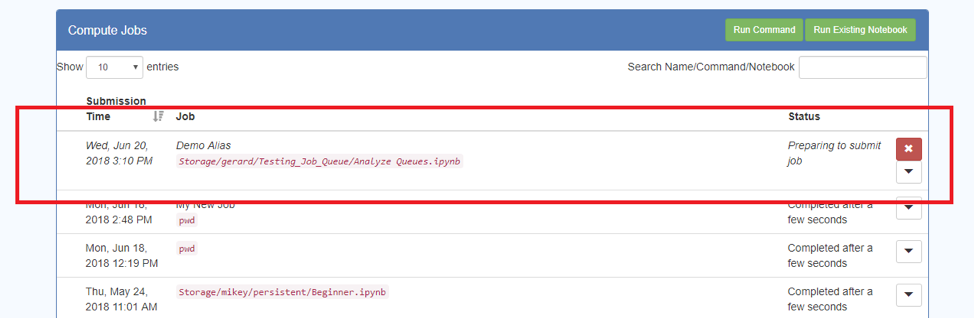
- After submitting a Job, and before it has completed execution, it can be cancelled.
- Display the Jobs table, and your running Jobs will be identified by having a red “X” next to them:
![]()
- Press the “X” button to cancel the job.
-
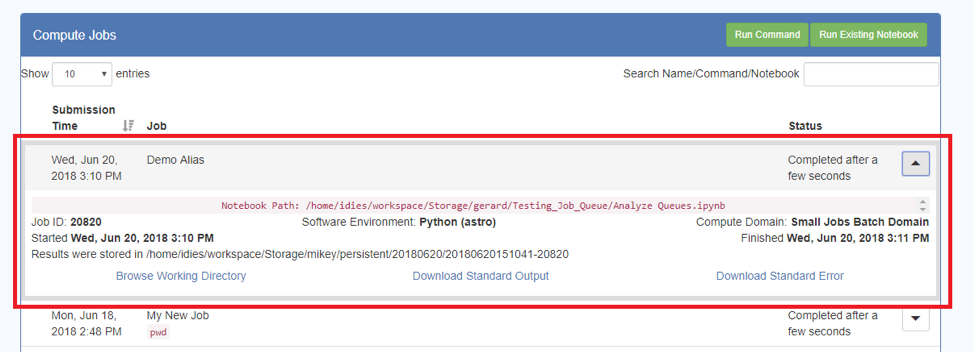
- When your job is complete the Jobs Table will display the status:
![]()
- The results output will go to the location specified in the Job Definition
- In the Jobs Table, expand the job of interest:
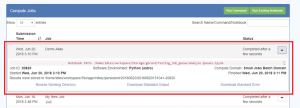
- This give status information about the Job, the path to the location of the results, and three hyperlinks:
- Browse Working Directory will take you to the Dashboard Files tab and show you the output files as well as the original Python Notebooks.
- Download Standard Output and Download Standard Error will allow you to download these two text files as appropriate. They will be downloaded according to your Browser settings.