
Hosted Datasets
SciServer hosts more than two Petabytes of scientific data in a variety of disciplines, including astronomy and fluid mechanics. Datasets come in two types:
Public Data Volumes can be accessed from SciServer Compute by mounting them onto a new container at the time you create the container.
Databases can be accessed from SciServer Compute by querying them with commands from the SkyServer.CasJobs module. See the SciServer module API Documentation to learn how to use these commands.
The sections below describe each of the datasets available through SciServer. Click on one of the gray bubbles to the right of the dataset name to expand the section and see full information about that dataset.
SciServer makes a number of datasets directly available in SciServer Compute in the form of Public Data Volumes. To use these data volumes in your research or education activities, you will need to mount them to a virtual container at the time you create that container. See the instructions on How to create a new container to learn how to mount a Public Data Volume.
The AstroPath data volume contains the public release of the AstroPath multiplex immunofluorescence slides, saved in the .zarr format, as well as associated metadata tables. It also includes processed data used in analysis for publications.
For more information on AstroPath, see the AstroPath project website.
The Galactic Archaeology with HERMES (GALAH) project uses the HERMES spectrograph on the Anglo-Australian Telescope at Australian National University to measure stellar parameters and abundances of more than 900,000 stars, including repeat observations of 50,000. HERMES measures high-resolution (R~28,000) spectra of 400 stars at a time.
Data Release 4 (DR4) is the most recent public release of GALAH. DR4 includes the following data for each of 917,588 stars in the Milky Way, in the survey area shown below:

- Reduced one-dimensional spectra across the four wavelength regions of the HERMES spectrograph, from about 4700 to 7900 Ångstroms
- Barycentric radial velocity, including secondary stars in binary systems
- Stellar parameters including effective temperature, surface gravity, iron abundance, microturbulence, and broadening
- Up to 30 elemental abundances per star, including
- light elements: Li, C, N, O
- odd-Z elements: Na, Al, K
- α-elements: Mg, Si, Ca, Ti
- iron-peak elements: Sc, V, Cr, Mn, Co, Ni, Cu, Zn
- light and heavy slow neutron capture elements: Rb, Sr, Y, Zr, Mo, Ba, La, Ce, Nd
- rapid neutron capture elements: Ru, Sm, Eu
- Three value-added catalogues:
- Galactic orbital properties
- Crossmatches to Gaia DR3, 2MASS, and WISE with the contents of those catalogs
- 3D NLTE lithium abundances
For more details about the data, see the GALAH Data Release 4 page.
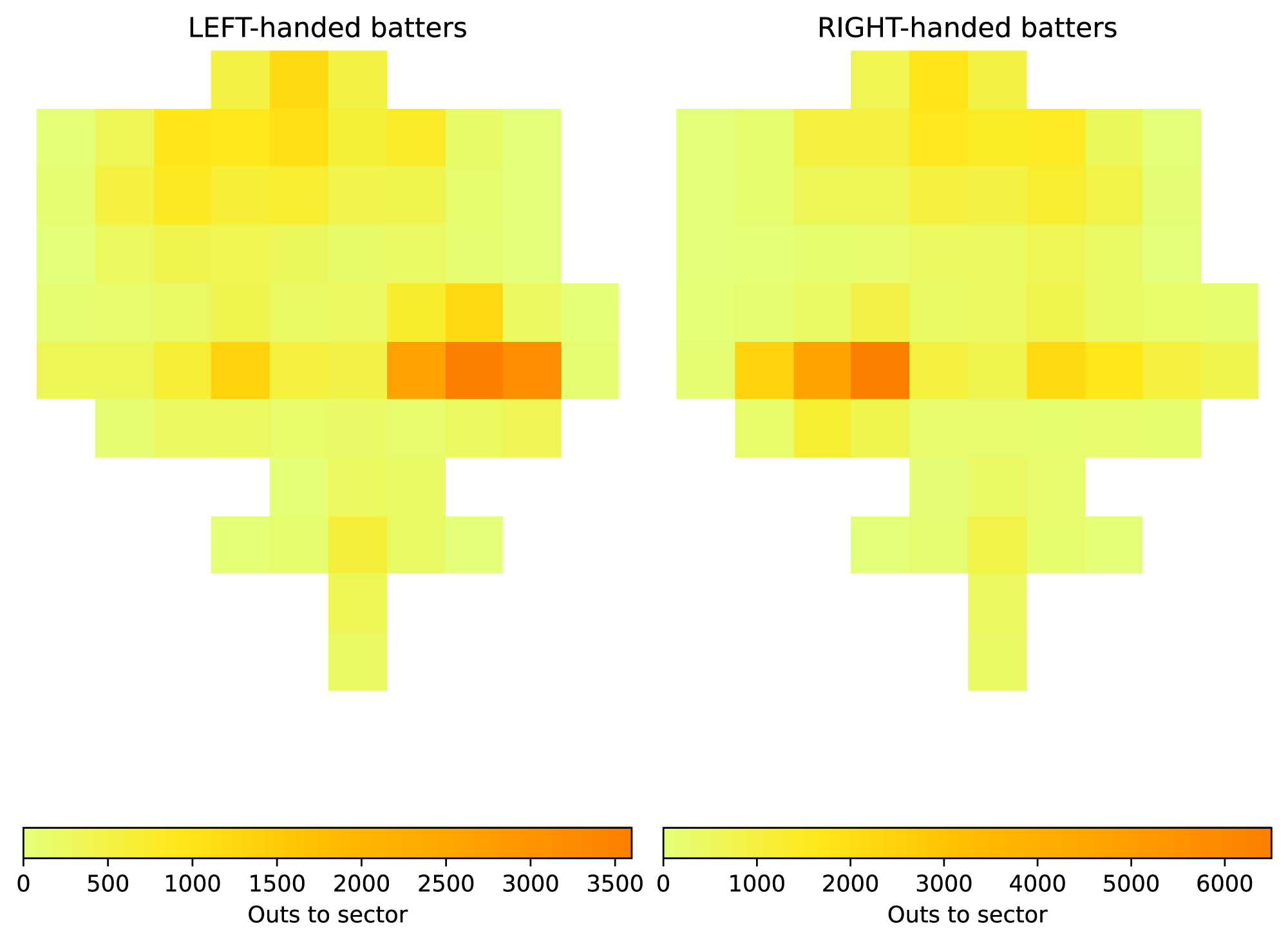
SciServer’s Getting Started public data volume contains example notebooks to help you learn how to use our science platform in your research and teaching. Now, we also feature datasets and accompanying notebooks designed to introduce the concepts and skills of data science. Our first example dataset comes from one of the most visibly data-intensive activities in American culture: baseball.
Our baseball getting started big dataset documents the history of Major League Baseball events. Every at-bat since 1974 is included, with some as far back as 1915. The dataset consists of CSV files, one per season. Each row represents one event – one at-bat, or a similar event such as a stolen base.
The Getting Started public data volume also includes one example notebook with one of many possible use cases – making the plot shown here of which section the ball travels to on outs in the 2022 season – with more to follow. Example notebooks working with the baseball dataset can be found in getting_started/Example-Notebooks/baseball/.
Events are transcribed from official records by volunteers with the Retrosheet website. For the structure of the files, see Retrosheet’s Description of Event Files.
Data Usage
Recipients of Retrosheet data are free to make any desired use of the information, including (but not limited to) selling it, giving it away, or producing a commercial product based upon the data. Retrosheet has one requirement for any such transfer of data or product development, which is that the following statement must appear prominently:
The information used here was obtained free of charge from and is copyrighted by Retrosheet. Interested parties may contact Retrosheet at 20 Sunset Rd., Newark, DE 19711.
The Satellite Mergers Usher Disc Galaxy Evolution (SMUDGE) simulations are a set of four high-resolution, N-body dynamical simulations of disk galaxies with each simulation containing over a billion particles. This suite includes two different models of isolated, disk galaxies and two versions in which these same disk galaxies experience a minor merger with a satellite galaxy.
This data volume contains about 154 TB of data, consisting of snapshots for each of the timesteps of the simulations. Each snapshot contains positions and velocities for the dark matter and ‘star’ particles, and the example Jupyter Notebook (available as part of the SMUDGE GitHub project and also stored in SMUDGE/data01_01, see the SMUDGE Dataset page for more detail) shows how to access both the individual timestep snapshots and trajectories (orbits) for individual ‘star’ particles over a given time period.
For more information, see the following references:
- For full details of the simulations and the primary citation, see Hunt et al. 2021
- Initial conditions for the host were taken from Widrow & Dubinski 2005, and generated using
Galactics(Kuijken & Dubinski 1995) - The satellite is the L2 model from Laporte et al. (2018)
- The simulations were run with the GPU accelerated N-body tree code
Bonsai(Bédorf et al. 2012)
For details about the data, see the SMUDGE Dataset page.
For more information on the AM Bench datasets available through SciServer, see the AM Bench Datasets page.
To learn how to get started using AM Bench data in SciServer, see the Getting started with AM Bench in SciServer page.
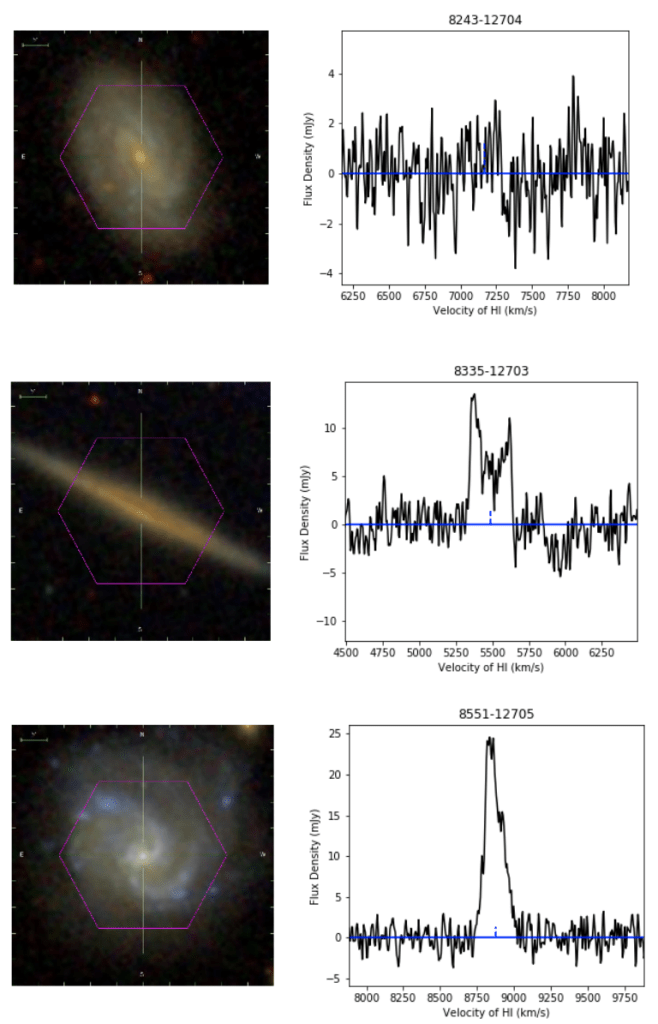
The SDSS Associated Data data volume provides easy access to useful datasets from the Sloan Digital Sky Survey that are not part of the official SDSS data releases (the latest of which is now Data Release 17).
Currently this data volume includes the one dataset described below. We will continue to add new datasets, including future SDSS value-added catalogs.
HI-MaNGA: HI followup observations of MaNGA target galaxies
The HI-MaNGA dataset consists of followup observations of MaNGA galaxies in the HI (21 cm) wavelength, using the Green Bank Telescope. The observations were designed to address scientific questions related to stellar evolution and gas accretion in various types of galaxies. The final dataset will include most galaxies in the MaNGA catalog with z < 0.05.
For more information about the HI-MaNGA dataset, see its description page on the SDSS website.
SDSS Spectra Data Volume contains spectra of millions of stars, galaxies, and quasars from the Sloan Digital Sky Survey (SDSS), an ongoing effort to make a three-dimensional map of the Universe.
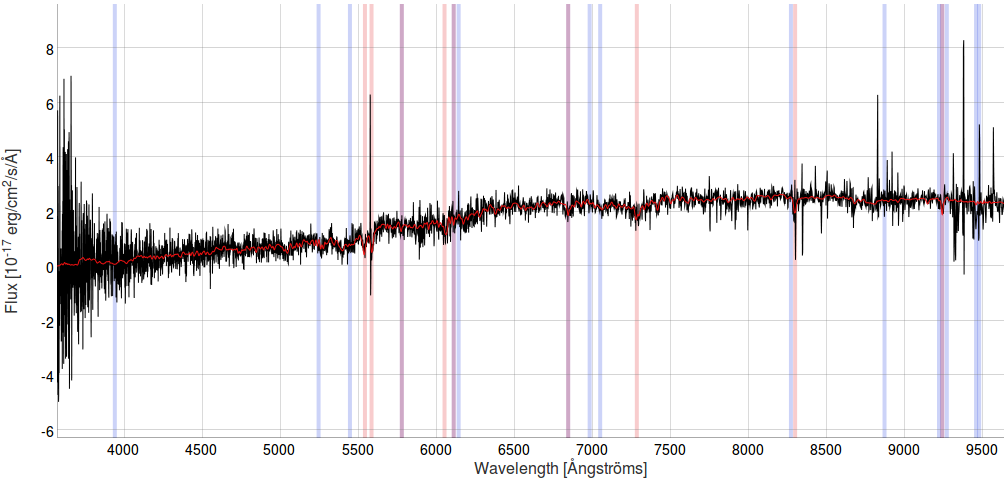
If you have a SciServer account, you can see the contents of this data volume in your Dashboard by going to the Files tab, or with this direct link to the SDSS Spectra Data Volume (for logged-in users only). Catalog data from the same spectra are also available on SciServer; see Sloan Digital Sky Survey Catalog Archive Data under Databases below.
To use the SDSS spectroscopic data in your work in SciServer Compute, create a new container and check the box to mount the SDSS Spectra onto your container.
About the Data
The observations come from the SDSS’s component extended Baryon Oscillation Spectroscopic Survey (eBOSS), which has measured optical spectra (3600-10400 Ångstroms) for millions of galaxies and quasars.
Individual spectra are available as FITS files. Each file follows the structure of the SDSS spec-lite file format, containing the coadded spectrum (HDU 1 COADD), spAll row (HDU 2 SPALL), and spZline row (HDU 3 SPZLINE) – but not the individual exposures (HDUs 4+), which are available only through the equivalent full spec files on the Science Archive Server.
For a full description of the file format, see the documentation of SDSS spec files from the SDSS data model.
The same FITS files can also be accessed through the SDSS Science Archive Server website, along with many related files describing various aspects of the SDSS spectroscopic data model.
Data Volume structure
The root level of the Data Volume contains the single directory spec-lite, indicating that the contents are SDSS spec-lite files. The next level down organizes the data by run2d, which indicates which version of the SDSS spectroscopic pipeline had been run to process the spectra in that subfolder. Because different pipeline versions were used by different surveys and programs, the run number indicates when and why the spectra were collected.
The most recent spectra come from SDSS Data Release 16 and have run2d value v5_13_0; most users will want this version. The list below shows which run2d values correspond to which datasets.
Within each run2d directory, spectra are organized by the SDSS plate used for the measurement; each plate-based directory contains either 640 or 1,000 FITS files, one for each spectrum collected by the plate.
Guide to run2d numbers
v5_13_0contains all optical spectra released as part of Data Release 16v5_10_0contains all optical spectra released as part of Data Release 14104contains all optical spectra collected by the SDSS SEGUE-2 survey in 2008-2009, and some other preliminary spectroscopic data collected in the same period, first released in DR7103contains all optical spectra collected by the SDSS SEGUE-1 survey’s cluster studies in 2004-2008 (part of DR7)26contains all other optical spectra from SEGUE-1 and the original SDSS Legacy Survey, observed 2000-2008 and released in DR7
The following query gives summary data about each of these runs, including the SDSS survey and program responsible for the data:
select cast(run2d as int) as run, survey, programname, count(*) as nPlates, min(dateObs) as startDate, max(dateObs) as endDate
from platex
where run2d in ('26','103','104')
group by cast(run2d as int), survey, programname
order by cast(run2d as int), survey, programname
The HEASARC data volume contains a copy of all of the public data hosted at the High-Energy Astrophysics Science Archive Research Center (HEASARC). For information about the various missions available and how to use specific datasets, please see the HEASARC website and/or contact our helpdesk from that site’s Feedback link at the bottom.
The HEASARC data volume also includes a software area for miscellaneous additional things such as interactive cookbooks that are under development. Some startup instructions can be found on the HEASARC SciServer documentation page. The software environment to analyze these data can be found in the Compute Image called HEASARCv6.28.
Indra is a suite of large-volume cosmological N-body simulations. Each of the 384 simulations is computed with the same cosmological parameters and different initial phases, providing excellent statistics of the large-scale features of the distribution of dark matter.
The independent volumes have 10243 dark matter particles in a box of length 1 Gpc/h, and are all accessible through SciServer Compute containers to all users who join the Cosmology science domain. A full description of the Indra suite of simulations can be found in a paper by Falck, et al (2021).
The Indra data volumes contain, for each simulation:
- 64 snapshots of particle positions and velocities
- 64 snapshots of FOF and SUBFIND halo catalogs
- 505 time-steps of coarse-gridded Fourier-space density fields
Indra data are accessed with the indra-tools python package pre-installed on the Computational Simulations compute image. The indra-tools git repository contains example notebooks showing how to read the binary data, query the halo database tables, compute density fields, etc.
Use of the Indra dataset is open and available to anyone. We ask that scientific publications that make use of Indra cite the Falck, et al (2021) data release paper.
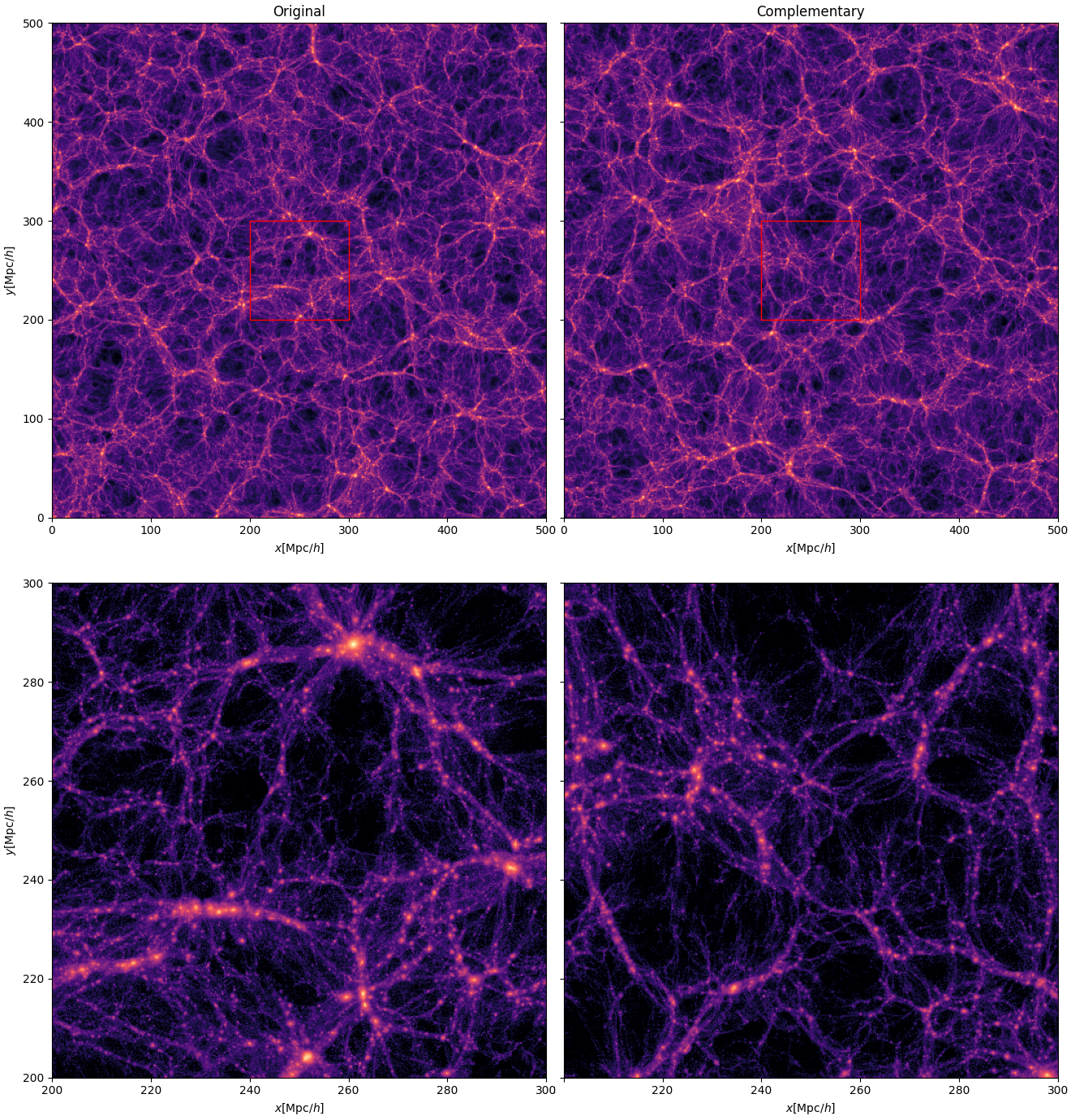 MillenniumG4 and MillenniumG4_Complementary are a matching pair of cosmological N-body simulations.
MillenniumG4 and MillenniumG4_Complementary are a matching pair of cosmological N-body simulations.To minimize the effects of cosmic variance, the averaged initial power spectrum of the pair was set to exactly match the cosmic average power spectrum. These simulations were started from inverted phases relative to each other. As a consequence, the structure formation is inverted in the pair: a region that collapses to a halo in the original Millennium run tends to expand into a void in the corresponding complementary pair and vice versa. Since the amplitudes are also compensated with the complementary pair, the average statistical quantities of a pair of such simulations are expected to remain consistent with the non-linear state-of-the-art estimation methods even at late times. This makes this pair ideal for estimating the effects of the cosmic variance in the original Millennium simulation.
This data volume contains two simulations:
- MillenniumG4 is a re-simulation of the original Millennium Simulation. It has the same cosmological parameters, resolution, linear size, softening, integration accuracy, initial phases and amplitudes as the original simulation, but it was run with the more recent and publicly available GADGET-4 simulation code.
- MillenniumG4_Complementary is the complementary simulation of the MillenniumG4. This simulation has the same cosmological parameters, resolution, linear size, softening and integration accuracy as the MillenniumG4 simulation, but it has modified initial amplitudes with inverted phases. It was run with GAGDET-4.
The following datasets are available for each simulation:
- 64 snapshots of dark matter particle coordinates and velocities
- 64 power spectra of each particle snapshot
- 64 snapshots of dark matter FOF halo and SUBFIND subhalo catalogues
- 64 reconstructed NGP density fields on a 256^3 grid
While by itself the original simulation was not large enough to resolve the baryonic wiggles in the power spectrum due to the sample variance at the low-k modes, the average power spectrum of the original and complementary Millennium simulation are able to directly follow the evolution of the baryon acoustic oscillation features.
If you plan to publish an academic paper using this data volume, please consider citing the Rácz, et al (2022) publication.
This volume contains all the raw and processed file-based data from Data Release 7 (DR7) of the Sloan Digital Sky Survey (SDSS). The raw and pipeline-processed imaging and spectroscopic data products are available here (mostly) in binary FITS format.
The data on the SDSS-DAS volume can be accessed via SciServer Compute using the standard file access python tools. A copy of this data is also accessible via the SDSS DAS website, and the catalog version of this data is available from the SDSS DR7 SkyServer.
Recount2 provides processed and summarized expression data for over 70,000 human RNA-seq samples from the Sequence Read Archive (SRA), The Cancer Genome Atlas (TCGA), and The Genotype-Tissue Expression (GTEx) project (https://doi.org/10.1038/nbt.3838).
The associated Bioconductor package provides a convenient API for querying, downloading, and analyzing the data. Each processed study consists of meta- and phenotype data, the expression levels of genes and their underlying exons and splice junctions, and corresponding genomic annotation. By taking care of several preprocessing steps and combining many datasets into one easily-accessible website, we make finding and analyzing RNA-seq data considerably more straightforward.
SciServer hosts numerical model output of high-resolution Ocean General Circulation Models (GCMs) set up and run by the research group of Prof. Thomas W. N. Haine (Johns Hopkins University – Department of Earth and Planetary Sciences).These models allow users to trace the physical evolution of ocean currents across orders of magnitude in space and time, and to quickly analyze important aspects of model events in conjunction with observational data.
The goal of the SciServer Ocean Modeling User Case is to build a collaborative sharing environment where users can access and process high-resolution datasets. The analysis of these large datasets is often restricted by limited computational resources, so we have developed OceanSpy, a python package that facilitates extracting information from model output fields. SciServer users can either download subsets of data on their own machines, or run our tools online and store post-processing files on our servers.
Available Datasets
- EGshelfIIseas2km_ERAI: High-resolution (~2km) numerical simulation covering the east Greenland shelf (EGshelf), and the Iceland and Irminger Seas (IIseas). Surface forcing based on the global atmospheric reanalysis ERA-Interim (ERAI). Citation: Almansi et al., 2017
- EGshelfIIseas2km_ASR: High-resolution (~2km) numerical simulation covering the east Greenland shelf (EGshelf),and the Iceland and Irminger Seas (IIseas). Surface forcing based on the regional atmospheric Arctic System Reanalysis (ASR). Citation: Almansi et al., 2017
- EGshelfSJsec500m: Very high-resolution (500m) numerical simulation covering the east Greenland shelf (EGshelf) and the Spill Jet section (SJsec). Both hydrostatic and non-hydrostatic setup are available. Citation: Magaldi and Haine, 2015
References
- Almansi, M., T.W. Haine, R.S. Pickart, M.G. Magaldi, R. Gelderloos, and D. Mastropole, 2017: High-Frequency Variability in the Circulation and Hydrography of the Denmark Strait Overflow from a High-Resolution Numerical Model. J. Phys. Oceanogr., 47, 2999–3013, https://doi.org/10.1175/JPO-D-17-0129.1.
- Marcello G. Magaldi, Thomas W.N. Haine, Hydrostatic and non-hydrostatic simulations of dense waters cascading off a shelf: The East Greenland case, Deep Sea Research Part I: Oceanographic Research Papers, Volume 96, 2015, Pages 89-104, ISSN 0967-0637, https://doi.org/10.1016/j.dsr.2014.10.008.
SciServer offers a number of catalog datasets in the form of online SQL databases. These databases can be queried directly through CasJobs. From the CasJobs Query page, select a dataset from the Context menu to choose what to query. Enter your query in the query box, then click Quick (to return results to your browser, limited to 90 seconds) or Submit (to write results into your MyDB.All these databases can also be queried from within SciServer Compute by using the SciServer API libraries. You do not have to mount anything to query these databases, and the libraries will work from within any container.
Simply import these libraries into your scripts, then make use of them. Information about how to use the libraries, and what commands are available, can be found in the SciServer API libraries documentation. Examples of how to query databases are available in the SciServer Example Notebooks.
The SkyMapper Southern Survey (SMSS) is a 6-band optical survey conducted with the Australian National University’s 1.3m SkyMapper Telescope at Siding Spring Observatory in Australia. The telescope has a 32-CCD mosaic camera, with 268 million pixels, covering 2.4° x 2.4°. The SMSS filter set (Bessell et al. 2011) is comprised of u, v, g, r, i, and z, with differences from the SDSS and LSST/VRO bandpasses that facilitate novel scientific applications.
SMSS published its Fourth Data Release (DR4) in February 2024, covering from the South Celestial Pole to Declinations of +16°, with some fields observed up to +28°. Approximately 700 million unique sources have been observed from 15 billion photometric data points measured from over 400,000 images acquired between March 2014 and September 2021.
The typical 10-sigma depths for each field range between 18.5 and 20.5 mag, depending on the filter, but certain sky regions include longer exposures that reach as deep as 22 mag in some filters.
For more information about SMSS and DR4, see the SkyMapper website or consult the SMSS DR4 paper (Onken et al. 2024).
SciServer hosts the master, images, ccds, and mosaic tables from SkyMapper DR4. To query these tables using CasJobs, select SkymapperDR4 from the Context menu just above the query window. To access it using SciServer Compute, specify its name as the context in the appropriate place in your SciServer.CasJobs.executeQuery(sql, context) or SciServer.CasJobs.submitQuery(sql, context) commands: for example, as:
SciServer.CasJobs.executeQuery("select top 10 * from master", context="SkymapperDR4")
The XMATCH database contains data from more than 50 astronomical surveys, along with SQLxMatch code to run 2-dimensional spatial cross-matches between these catalogs, or against catalogs of point sources that you upload into your MyDB.
You can run the SQLxMatch code and query the XMATCH tables from a Jupyter Notebook running in a SciServer Compute container. An example notebook is available in the shared Getting Started data volume, in the Astronomy/Cross-Match of Source Catalogs folder. You can also download the example notebook directly from the SQLxMatch GitHub repository. Once you have the example notebook in your persistent folder, you can adapt it to meet your needs.
Documentation on the SQLxMatch code is available in the README of its GitHub repository.

The Large Sky Area Multi-Object Fiber Spectroscopic Telescope (LAMOST) is a Chinese national scientific research facility operated by the National Astronomical Observatories, Chinese Academy of Sciences.
It is a special reflecting Schmidt telescope with 4000 fibers in a field of view of 20 square degrees. The LAMOST survey provides flux – and wavelength-calibrated, sky-subtracted spectra in the wavelength range of 3700-9000 Ångstroms for many types of astronomical objects. Since October 2018, LAMOST started the second stage survey program containing both low- and medium-resolution spectroscopic surveys, and the medium-resolution spectroscopic survey includes two surveys, i.e., the time-domain and the non time-domain surveys.
The eighth LAMOST data release (LAMOST DR8) includes observations until June 2020. The Low-Resolution spectroscopic survey (LRS) General Catalog contains 10,633,515 spectra, of which 10,336,752 are stars, 224,702 are galaxies, 72,061 are QSOs, and there are 9,563,115 spectra with g-band SNR or i-band SNR larger than 10. The Medium-Resolution spectroscopic survey (MRS) General Catalog contains 5,975,982 spectra, where there are 1,465,789 and 4,510,193 spectra for the non time-domain and time-domain surveys, respectively. (Note: This catalog totally contains 22,141,635 entries, which is different from the two statistics numbers above. For the number of the non-time-domain survey, we only count each of the coadded spectra as one of the 1,465,789 spectra, while for the time-domain survey, every single exposure of the B band plus R band were regarded as one of the 4,510,193 spectra.)
SciServer hosts version 2 of the DR8 release (DR8v2). In addition to the LRS and MRS General Catalogs, LAMOST DR8 provides many other catalogs, including stellar parameter catalogs, the Observed Plate Information Catalog, the Input Catalog and others. Refer to the data product description pages for the Low-Resolution Spectrocopic Survey (LRS) and Medium-Resolution Spectrocopic Survey (MRS) for more information on this data release.
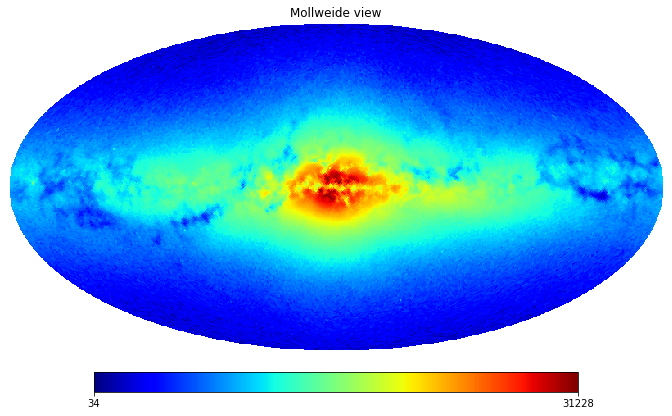
The ApogeeFire database context contains a large catalog of mock stars in mock Milky Way-like galaxies, created using the FIRE2 framework (Wetzel et al. 2016).
Mock data for each mock star includes radial velocity, proper motion, chemistry (10 chemical elements are tracked in the simulation), parallax, and photometry in the Gaia bands.
You can query the catalog directly from CasJobs by selecting ApogeeFire from the Context dropdown menu.
You can also use Jupyter notebooks in SciServer Compute to analyze and visualize data from this catalog. For an example, go to SciServer Compute, create a new container, and mount the getting_started Data Volume. Navigate to Astronomy/apogee_fire, then select the IPython notebook apogee_fire_intro.ipynb. Download it and upload it into your Storage/persistent space. Use this example notebook as a starting point for your analysis.
Science
Mock catalogs of sophisticated galaxy simulations provide unique opportunities for observational projects, in particular, the ability to test for or constrain the impact of selection functions, field plans, and algorithms on the scientific inference being made.
One of the most realistic galaxy simulations to date is the Latte simulation suite that uses the FIRE2 framework to produce Milky Way galaxies (Sanderson et al. 2020); these include radial velocity, proper motion, chemistry (10 chemical elements are tracked in the simulation), parallax, and photometry in the Gaia bands, among others.
Because the input physics and the global structure of the model galaxy are known, these mock catalogs provide a rare experimental laboratory to make connections between the resolved stellar populations and global galaxy studies — the key driver in the Milky Way as a Galaxy working group (MWAG). With Nikakthar et al. (2021), the Ananke simulations are updated with APOGEE-2 specific properties (e.g., selection photometry) and are suitable for broad use. With this VAC, we provide the APOGEE-suitable simulations along-side the APOGEE-2 data providing a unique tool for Galactic inferences.
Data Model
There are 73 columns as listed in the original Ananke catalog, plus the following new columns relevant for APOGEE:
- Stellar abundances as they would be measured by APOGEE (10 columns per star)
- Stellar abundance measurement uncertainties (10 columns)
- 2MASS JHKs magnitudes: “observed” magnitudes, intrinsic (unreddened) magnitudes, true (reddened/extincted but not error-convolved) magnitudes, and photometric uncertainties for all stars (12 columns)
- Column applying Ted Mackereth’s APOGEE sky footprint selection function (1 Boolean column)
The final catalog thus contains 106 columns.
You can view the data model through the CasJobs Schema Browser by selecting the ApogeeFire context from the dropdown. More detail on the columns is available from the APOGEE_FIRE_SIM entry of the SDSS data model.

Indra is a suite of large-volume cosmological N-body simulations. Each of the 384 simulations is computed with the same cosmological parameters and different initial phases, providing excellent statistics of the large-scale features of the distribution of dark matter.
The independent volumes have 10243 dark matter particles in a box of length 1 Gpc/h, and are all accessible through SciServer Compute containers to all users who join the Cosmology science domain.
A full description of the Indra suite of simulations can be found in a paper by Falck, et al (2021).
The Indra relational database contains:
- Halo catalog tables for every simulation and snapshot
- Spatial3d library to allow efficient selection of halos and particle data within 3D shapes
Indra data are accessed with the indra-tools python package pre-installed on the Computational Simulations compute image. The indra-tools git repository contains example notebooks showing how to read the binary data, query the halo database tables, compute density fields, etc.
Use of the Indra dataset is open and available to anyone. We ask that scientific publications that make use of Indra cite the Falck, et al (2021) data release paper.
The Sloan Digital Sky Survey (SDSS) is an ongoing project to make a map of the Universe. It has observed images of hundreds of millions of stars and galaxies, and spectra for more than four million.The entire history of data releases from the Sloan Digital Sky Survey (SDSS) can be queried through SciServer Compute by importing and using the SciServer libraries.
The SDSS releases its data in discrete batches through sequentially-numbered Data Releases. The most recent is Data Release 17 (DR17); for new studies with SDSS data, begin with DR17. To enable replication and extension of prior studies, we make all previous data releases (DR1 through DR16) available as well. We also provide two additional datasets: Stripe82 contains all photometric data for the repeat observations of the SDSS supernova survey, while RunsDB contains all photometric data for all SDSS observations, including overlap areas.
To query one of the SDSS databases using CasJobs, select its name from the Context menu just above the query window. The contexts holding SDSS data are DR17, DR16, etc.
To access one of the SDSS databases using SciServer Compute, specify its name as the context in the appropriate place in your SciServer.CasJobs.executeQuery(sql, context) or SciServer.CasJobs.submitQuery(sql, context) commands: for example, as
SciServer.CasJobs.executeQuery("select top 10 * from photoobj", context="DR17")
Gaia is a European Space Agency mission to find distances and properties of more than one billion stars in our Milky Way Galaxy.SciServer hosts the complete catalog data for Gaia Early Data Release 3 (Gaia EDR3).
To query the Gaia EDR3 catalog using CasJobs, select GaiaEDR3 from the Context menu just above the query window. To access Gaia EDR3 data using SciServer Compute, specify its name as the context in the appropriate place in your SciServer.CasJobs.executeQuery(sql, context) or SciServer.CasJobs.submitQuery(sql, context) commands: for example, as
SciServer.CasJobs.executeQuery("select top 10 * from gaia_source", context="GaiaEDR3")
The Galaxy Evolution Explorer (GALEX) is an ultraviolet space telescope that operated from 2003 to 2012. During that time, it observed hundreds of thousands of galaxies, helping to determine distances and star formation rates throughout the universe. SciServer offers access to all GALEX releases up to and including its final complete dataset, GALEX Release 6 (GR6). The GALEX data releases are referred to in SciServer as GALEXGR6, GALEXGR5, etc.To query one of the GALEX databases using CasJobs, select its name from the Context menu just above the query window.To access one of the GALEX databases using SciServer Compute, specify its name as the context in the appropriate place in your SciServer.CasJobs.executeQuery(sql, context) or SciServer.CasJobs.submitQuery(sql, context) commands: for example, as
SciServer.CasJobs.executeQuery("select top 10 ra, dec from acsData", context="GalexGR6")
The Two Micron All-Sky Survey (2MASS) is an all-sky survey at infrared wavelengths. SciServer offers access to the Point Source Catalog of the 2MASS All-Sky Data Release, enabling studies of populations of stars and other resolved objects in the Milky Way.To query this catalog using CasJobs, select 2MASS from the Context menu just above the query window. To access it using SciServer Compute, specify its name as the context in the appropriate place in your SciServer.CasJobs.executeQuery(sql, context) or SciServer.CasJobs.submitQuery(sql, context) commands: for example, asSciServer.CasJobs.executeQuery("select top 10 * from PhotoObjAll", context="2MASS")
The Two-degree-Field (2DF) Galaxy Redshift Survey is an all-sky survey at visible wavelengths, with the goal of understanding the large-scale structure of galaxies.To query this catalog using CasJobs, select 2DF from the Context menu just above the query window. To access it using SciServer Compute, specify its name as the context in the appropriate place in your SciServer.CasJobs.executeQuery(sql, context) or SciServer.CasJobs.submitQuery(sql, context) commands: for example, asSciServer.CasJobs.executeQuery("select top 10 * from PhotoObjAll", context="2DF")
The Faint Images of the Sky at Twenty cm (FIRST) is an all-sky survey at radio wavelengths.To query this catalog using CasJobs, select FIRST from the Context menu just above the query window. To access it using SciServer Compute, specify its name as the context in the appropriate place in your SciServer.CasJobs.executeQuery(sql, context) or SciServer.CasJobs.submitQuery(sql, context) commands: for example, asSciServer.CasJobs.executeQuery("select top 10 * from PhotoObjAll", context="FIRST")
The Minor Planet Center Orbit (MPCORB) database contains orbital parameters for more than 700,000 asteroids from the International Astronomical Union’s Minor Planet Center. The dataset available through SciServer is a snapshot of the database as of August 17, 2017.To query this catalog using CasJobs, select MPCORB from the Context menu just above the query window. To access it using SciServer Compute, specify its name as the context in the appropriate place in your SciServer.CasJobs.executeQuery(sql, context) or SciServer.CasJobs.submitQuery(sql, context) commands: for example, asSciServer.CasJobs.executeQuery("select top 10 * from mpcorb", context="MPCORB")