
Future Plans
SciServer at AAS 2021 | Schedule | Astronomical Datasets | Cosmological Simulations | SciServer in the Classroom | Future Plans
SciServer has many exciting new features coming up over the next year or so. Learn about them here!
Big Data Cluster | MaNGA BDC | Kubernetes | DeepForge | GPU Computing
Big Data Cluster (BDC)
Big Data Clusters (BDC) is a microsoft solution that enables querying data across large distributed stores via T-SQL and Spark interfaces (more information is available at Microsoft’s Big Data Cluster site).
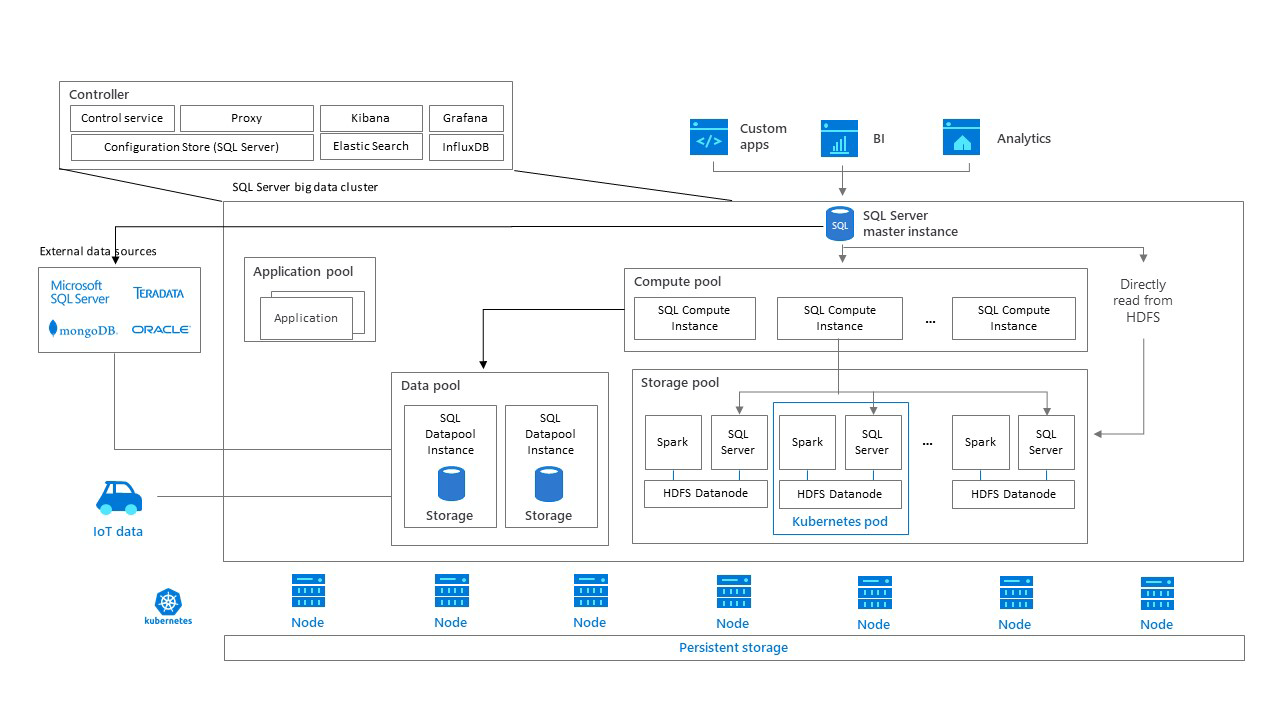
With BDC deployments within the SciServer datacenter, we can run workloads against these large datasets from within SciServer Notebooks (T-SQL queries via CasJobs API or Spark sessions) or via the CasJobs user interface (T-SQL queries), enabling easy access to large scale out datasets using both SQLServer and columnar file formats such as parquet.
The T-SQL interface to distributed parquet data storage provides a simple and familiar interface to run queries to large datasets from CasJobs. Ideal for search and discovery and group statistics, this fits well with a number of existing workloads.
The Spark interface allows powerful arbitrary code to be run against data including complex types such as structs and arrays, and is ideal for running ETL jobs such as reduction pipelines, and more sophisticated analysis across an entire dataset.
MaNGA Data in BDC
The SDSS MaNGA dataset is an astronomical dataset from the MaNGA program of the Sloan Digital Sky Survey. MaNGA stands for Mapping Nearby Galaxies at APO (Apache Point Observatory), and is a wide-field spectroscopic survey collecting integral field observations of ~10,000 galaxies, with a goal to map the detailed composition and kinematic structure by measuring spectra for hundreds of points within each galaxy.
For each galaxy, MaNGA produces a range of data products, including 3D spectroscopic Data Cubes, 2D Row-Stacked Spectra (RSS), along with a “model cube” file and “maps” file output from MaNGA’s Data Analysis Pipeline (DAP). The model cube file provides model spectra and relevant masks for every spectrum fit by the DAP. The maps files provide the relevant model properties useful for further science analysis.
For exploratory BDC work on SciServer, we are using the SDSS MaNGA public Data Release 15 (released 2018), which contains data products for 4857 galaxies, with a total data size of ~3.7 TB. The total number of files is:
- 4857 3D data cubes
- 4857 row-stacked spectra
- 9440 analysis maps (3 binning schemes)
- 9440 3D model spectral cubes (3 binning schemes)
Demo Notebooks
- manga_bpt_pyspark_example – MaNGA science use demonstrating use of PySpark to generate a BPT diagram using all ~4 millions spaxels of the MaNGA DR15 dataset
- postgres_pyspark_query_comparisons – a few benchmark comparisons between a Postgresql query, a PySpark DataFrame query, and a Spark SQL query on the MaNGA DR15 dataset
Kubernetes

We have invested in deploying SciServer on Kubernetes using the template deployment engine Helm. Several partner sites have already been deployed in this fashion allowing SciServer to be integrated into an institution’s data workflow with minimal effort.
Do you:
- Have large on-premise datasets you want to provide compute for?
- Want to simplify access to compute resources for users?
- Have more than one group using your system and want to support collaboration yet limit access?
- Need to host on-site?
In the short term, we can offer hands-on support for installation and management of SciServer – please contact us if you are interested!
Further out (dependent on availability of funding), we are interested in releasing SciServer as open source making it even simpler to use and contribute to!
DeepForge
Deepforge is a graphical development environment for deep learning and a graph engine that supports running workloads on SciServer.
While supporting Deepforge’s integration with SciServer, we are also exploring tighter integrations for enabling pipeline-like workflows within SciServer to benefit all users.
GPU Computing
At SciServer we are developing GPU compute domains, where users can attach to an NVIDIA GPU to accelerate workloads such as Convolutional Neural Networks and other machine learning tasks using popular frameworks like Tensorflow and PyTorch.
While GPU domains are not public at present, we welcome interested parties to contact us and explain their use-case.