SciServer supports a wide variety of science use cases, and our new Science Domains feature helps you get the most out your science.
When you join a Science Domain through the SciServer Dashboard, you immediately gain access to all public resources – such as databases, data volumes, and virtual computing environments – relevant to your research.
Currently we have one science domain defined: Cosmological Simulations. Joining it will give you instant access to more than 20 datasets containing full results of the Millennium and Indra cosmological Simulations.
To join a Science Domain, click on its name from the list, then click the Join button below its description in the main panel.
In the near future, we will create science domains for more areas, which will include an Astronomy domain that will contain all the SDSS databases.
Cosmological Simulations
The Cosmological Simulations science domain gives you access to the results of several modern numerical simulations of structure formation: Indra, related products from the Virgo consortium, and the Millennium Simulations.
The theoretical input for galaxy-scale physics and large-scale galaxy redshift surveys is provided by cosmological numerical simulations, which model the evolution of the Milky Way or the entire Universe. SciServer hosts several sets of these simulations, offering unified access and collaborative visualization tools for hundreds of TB of data.
The unique advantage of accessing these simulations through SciServer is the ease with which they can be compared with real astronomical observations.
For more information on what you can access through the Cosmological Simulations science domain, see the cosmological simulations section of the Hosted Datasets page.
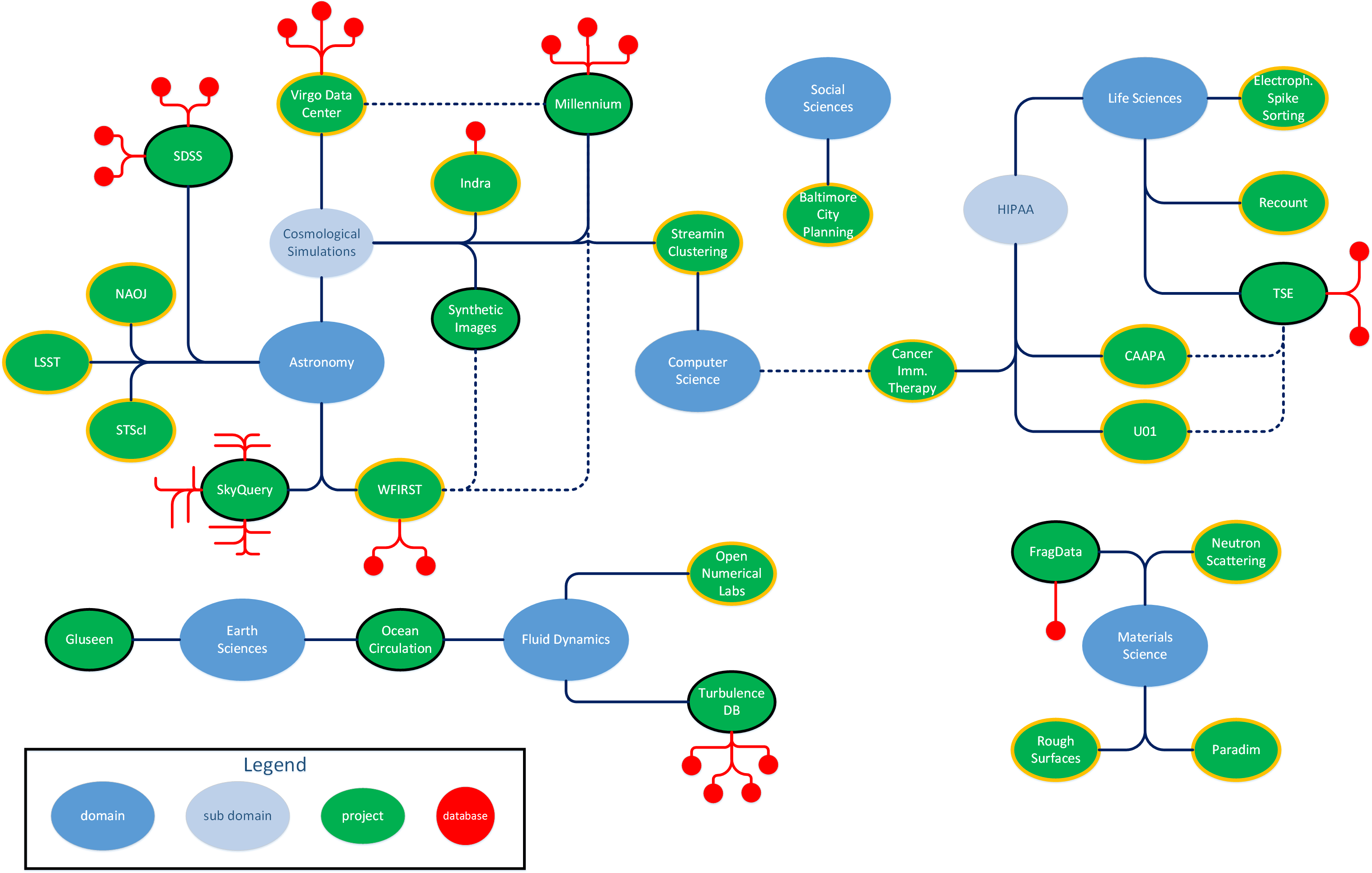
Diagram showing the science domains and projects supported by SciServer (click for a larger view).
SciServer comprises several scientific projects that have made their full datasets available in a common format and through a common set of interfaces. Many other projects will soon make their data available here as well.
The diagram shows SciServer’s projects, both those that currently make their datasets available through the SciServer environment and those that will in the future. Green ellipses mark specific projects, and red circles show those project’s databases. Blue ellipses map out which science domains these projects address. Click on the diagram for a larger view.
The list below gives the science domains addressed by SciServer’s current and future projects. Click on any of the icons for more information about that domain.
A screencapture of a tumor microenvironment in cellview. A magnified cell has florescent pink and green superimpositions and is sectioned with a cyan grid Researchers at the Mark Foundation Center for Advanced…
Another important application of large numerical simulations is in cosmological N-body simulations, which model the evolution of the Milky Way or the entire Universe. By 2016, SciServer will host several of these…
Turbulent fluid flow impacts a wide variety of engineering problems, but turbulence is mathematically complicated and poorly understood. One of the most productive research techniques is numerical simulation, but simulations powerful enough…
SciServer hosts numerical model output of high-resolution Ocean General Circulation Models (GCMs) set up and run by the research group of Prof. Thomas W. N. Haine (Johns Hopkins University - Department of…
The MEDE Data Science Cloud: SciServer Based Data Science for Materials Scientists and Engineers At Hopkins we’ve developed the Materials in Extreme Dynamic Environments Data Science Cloud (MEDE-DSC) to address the need…
Recent advances in sequencing technology have led to an explosive growth in the amount of publicly available human sequence data. This represents an invaluable opportunity for scientific exploration and discovery, but the…
Like other field sciences, soil ecology research requires detailed and consistent monitoring of natural conditions. The more researchers can monitor natural environments, the more they can discover - but long-term widespread studies…
SciServer is the official science platform for SDSS catalog data. SkyServer and CasJobs remain essentially the same, and now you can access them through SciServer, which lets you do so much more…