
History
Many key participants in SciServer were originally, and continue to be, part of the Sloan Digital Sky Survey (SDSS) and related projects. In its goal to map the Universe, SDSS generated an astronomical (pun intended) quantity of data. Dealing with it was a trial by fire. It brought us face to face with the challenge of storing, processing and understanding Scientific Big Data. The infrastructure necessitated by SDSS data was the birth of the system that became SciServer.
In addition to the general problem of dealing with Scientific Big Data, scientists over the years have grappled with many problems that originate from a lack of data infrastructure. Below are a few of the most serious problems we hope to address with SciServer. Scientists perusing this list will undoubtedly find it familiar, yet incomplete.
Just a few data-related problems scientists face are:
In addition to the general problem of dealing with Scientific Big Data, scientists over the years have grappled with many problems that originate from a lack of data infrastructure. Below are a few of the most serious problems we hope to address with SciServer. Scientists perusing this list will undoubtedly find it familiar, yet incomplete.
Just a few data-related problems scientists face are:
- Data preservation
- Ad hoc data storage format and media
- Insufficient metadata and incomplete documentation
- Unequal access to data and data processing resources
The SciServer project has its roots in 20 years of systems development at JHU, meeting the research needs of the Astronomy community. This development has supported SDSS, which has been gathering data since 2000. SDSS has seen three iterations, SDSS1 through SDSS33, and will continue in 2015 and beyond under SDSS4. Described as the "Cosmic Genome Project", the SDSS continues to be an impressive project.
SDSS has Increased Astronomical Data by three orders of magnitude (1000 times). From 200,000 galaxies we now know of more than 200,000,000 galaxies. This has revolutionized astronomy in unforeseen ways due to unprecedented sample sizes. SDSS has indded provided an embarrassment of riches,
The database to house SDSS data was built at JHU, as was the spectrograph used to collect galactic spectra. In addition, the Catalog Archive Server (CAS) and SkyServer were also developed at JHU in 1997 and 2001, respectively.
SDSS has Increased Astronomical Data by three orders of magnitude (1000 times). From 200,000 galaxies we now know of more than 200,000,000 galaxies. This has revolutionized astronomy in unforeseen ways due to unprecedented sample sizes. SDSS has indded provided an embarrassment of riches,
The database to house SDSS data was built at JHU, as was the spectrograph used to collect galactic spectra. In addition, the Catalog Archive Server (CAS) and SkyServer were also developed at JHU in 1997 and 2001, respectively.
The SDSS data access system, SDSS CAS, manages and serve up data to the scientific community. It is composed of three subsystems: SkyServer, CasJobs, and ImgCutout. SkyServer allows synchronous access to quick queries. CasJobs provides asynchronous access to more complex and time consuming queries. ImgCutout is used for visual browsing of images. All three systems interact with a Relational Database Management System to house and serve the data. The database schema was designed with scientific requirements in mind, and is heavily indexed to optimize queries.
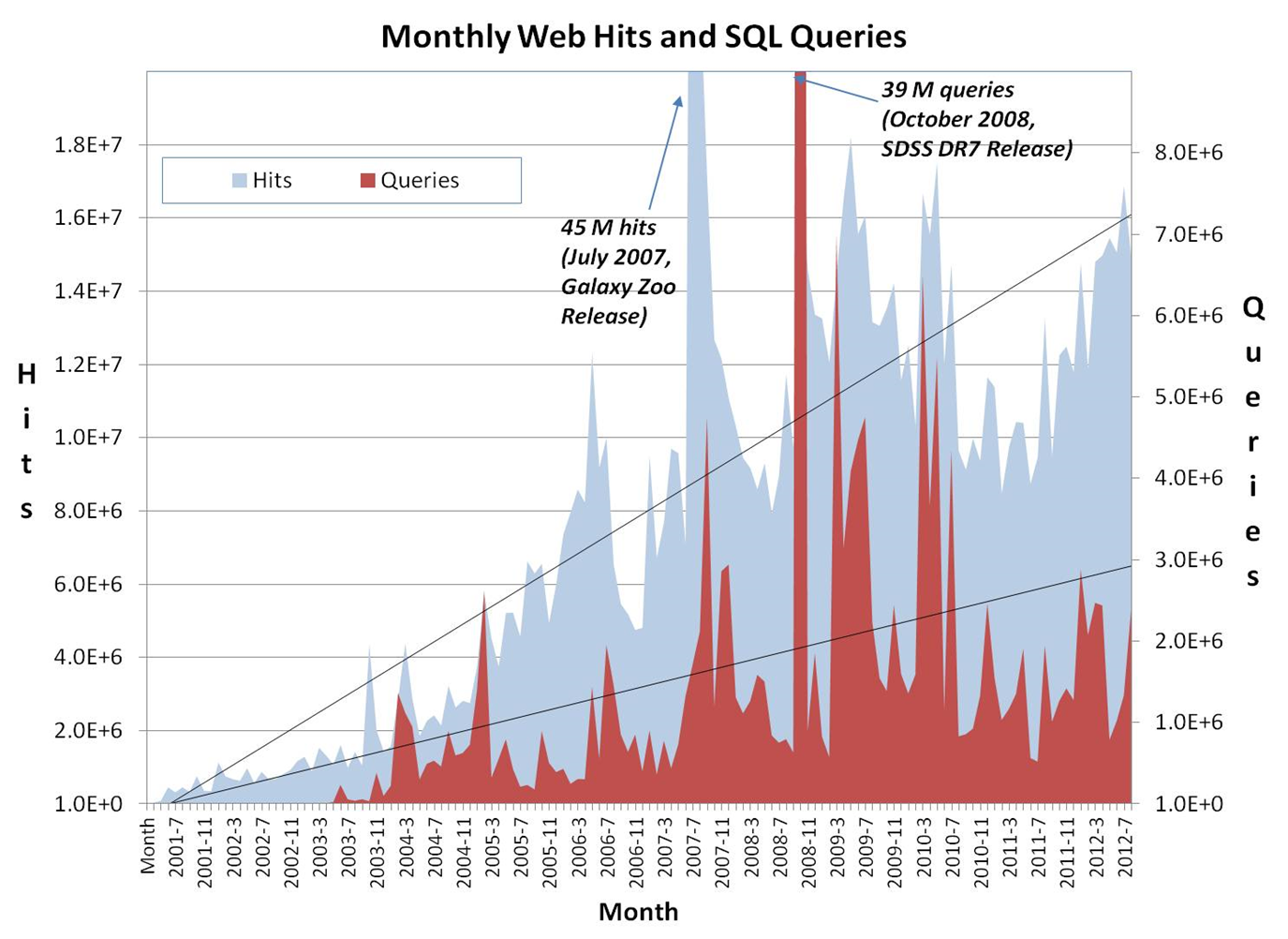 Analysis of website traffic shows that usage of the system has continually increased since the start of the project. Over that time both the number of visitors (shown in gray) and number of queries executed (shown in red) have increased. The system itself, including both the supporting hardware infrastructure and the software services themselves, has successfully scaled up to meet the demand throughout this period, and will continue to do so in the future, as necessary.
Analysis of website traffic shows that usage of the system has continually increased since the start of the project. Over that time both the number of visitors (shown in gray) and number of queries executed (shown in red) have increased. The system itself, including both the supporting hardware infrastructure and the software services themselves, has successfully scaled up to meet the demand throughout this period, and will continue to do so in the future, as necessary.In the figure below, consider the genealogy of existing SDSS applications. We see that the foundational components of SDSS data have already become the basis for numerous extensions and applications, even to other (non-astronomical) scientific data sets. The SDSS genealogy shows, for example, that the SkyServer framework has server as parent template for applications in the fields of turbulence (Turbulence Simulations), environmental science (Life Under Your Feet), and radiation oncology (Onco Space).

